
October 4th, 2017
A New Approach to Conversational Software
Alan Nichol

We're building the best way for your bot to hold a contextual conversation - and it's open source. Here's the repo.
In 2016, having spent more than six months building Slack bots, we wrote an article detailing some of the pieces we believed were missing in attempts to create great conversational software.
We don't know how to build conversational software yet
Since then, here at Rasa we've been doing applied research in this area and building tools to fill some of those gaps. In December 2016 we released Rasa NLU, which is now used by thousands of developers.
We're now getting ready to release Rasa Core, which is the most ambitious thing we've ever built. Let me describe what it is, how we got here, and where we're going next.
It's all about context
We've all seen bots hopelessly fail to manage context. This is such a well-known problem that it even featured on the ChatbotConf swag:

So what tools do developers need to do better than this? There's a lot of great research on using machine learning to solve this problem. But while there's been significant progress on this topic over the last decades, this hasn't translated into great developer tools.
The libraries available to bot developers today rely on hand-crafted rules. With Rasa Core we set ourselves the challenge of building a machine learning-based dialogue framework that's ready for production, flexible enough to support research and experimentation, and accessible to non-specialists.
Everyone uses state machines and state machines don't scale
Here are some of the home-brew approaches I've seen that people currently use to build stateful bots.
The most literal way to implement statefulness is to create a state machine.
Let's say we want to build a bot that helps users understand the products offered by a big bank. As a start, customers can ask about two things: mortgages and savings accounts. You want to let them compare options, so if someone asks a contextual question like *"which of those has a better interest rate?", *you need to know whether they are talking about a mortgage or a savings account.
A state machine implementation might look like the diagram below. You have states like mortgage_search and savings_search, plus some rules for switching between them given what the user just said.
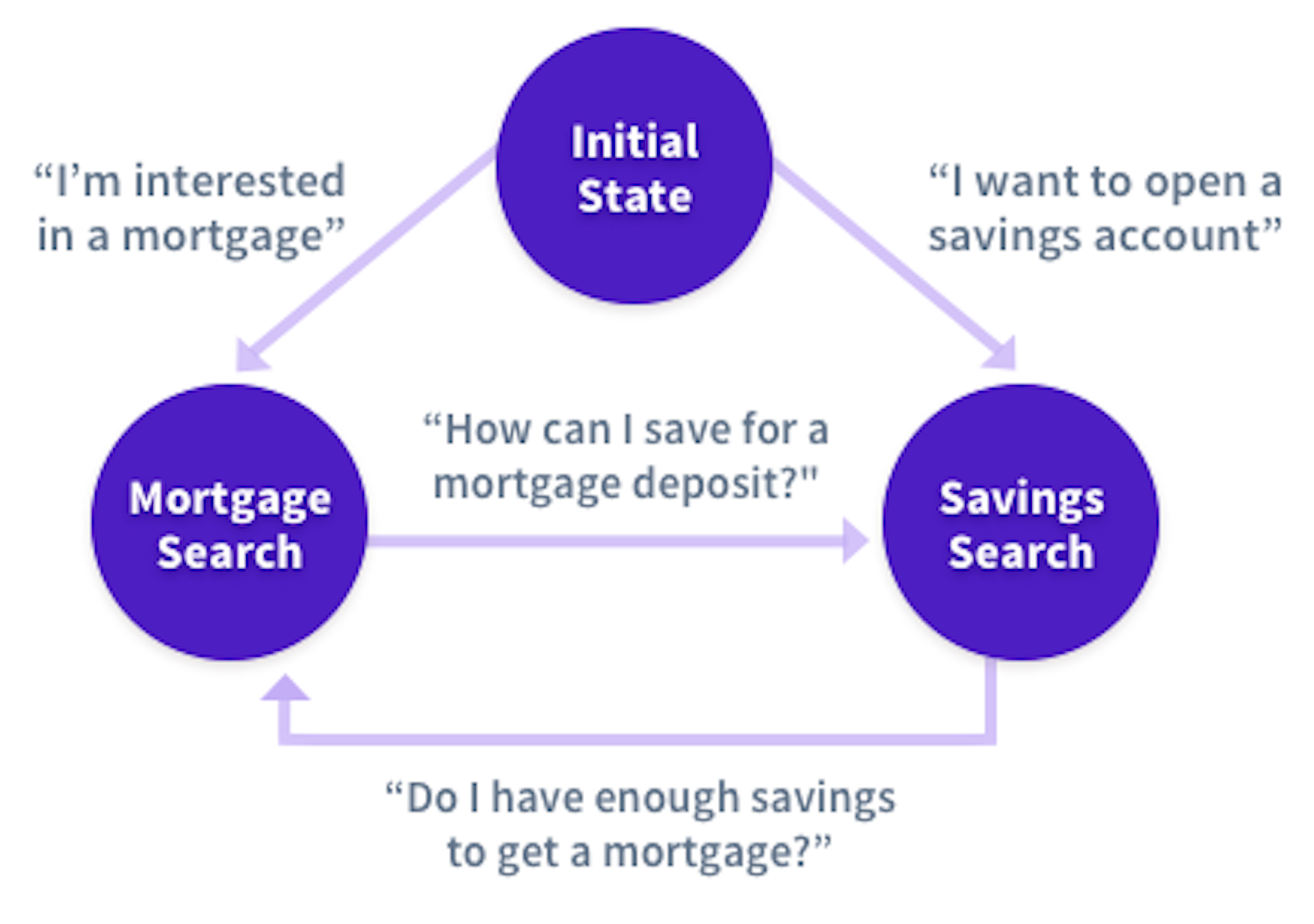
Here is some pseudocode showing how we might handle the compare_rates intent:
**if **intent == compare_interest:
**if **current_state == SAVINGS_SEARCH:
savings = tracker.recent_suggestions["savings"]
ActionShowSavingsInterest.run(savings)
**else if **current_state == MORTGAGE_SEARCH:
mortagages = tracker.recent_suggestions["mortgages"]
ActionShowMortgageInterest.run(mortgages)
**else**:
ActionNotSure.run()
Which is nice and simple, and sets us up for a conversation like this:

The happy path
Now if the user says, "Ok, I like the sound of the Super Saver", or "yeah let's do the second one", we can handle this as well (we'll call this the make_choice intent):
**if **intent == make_choice:
**if **current_state == SAVINGS_SEARCH:
# select the right savings account from suggestions
selected_account = resolve_choice(
entities,
tracker.recent_suggestions["savings"]
)
**if **selected_account **is not None**:
ActionStartAccountApplication.run()
** else**:
ActionAskWhichAccount.run()
**else if **current_state == MORTGAGE_SEARCH:
# select the right mortgage from suggestions
selected_mortgage = resolve_choice(
entities,
tracker.recent_suggestions["mortgages"]
)
**if **selected_account **is not None**:
ActionStartMortgageApplication.run()
** else**:
ActionAskWhichMortgage.run()
**else**:
ActionNotSure.run()
We've had to add some nested rules, but this is still pretty manageable.
Straying from the happy path
This is where things get hairy! How do you handle responses like:
"No I don't like the sound of either of those"
"How about the third one" (when there is no third one 😱)
Or further follow-ups like: "Why are the rates so different?"
One option is to add more levels of nested logic to the code above. Another is to add an extra state to your state machine, with another set of rules for how to get in and out of that state. Both of these approaches lead to fragile code that is harder to reason about. Anyone who's built and debugged a moderately complex bot knows this pain.
There are only a few happy paths, but the vast majority of conversations are "an edge case ... of an edge case ... of an edge case". Traditional IVR systems work this way, as do most chatbots currently. As a developer, you look through the thousands of conversations people have had, and manually add rules to handle each case. Then you test and realise that these clash with other rules you wrote earlier, and life becomes ever more difficult.
How the Research Community approaches dialogue: Reinforcement Learning
How can we use machine learning to move beyond the bag-of-rules approach? As I mentioned earlier, the last few decades have seen a lot of good research done on this topic.
Much of this has focused on using reinforcement learning (RL) to build systems which can learn complex tasks, purely by trying over and over and receiving a reward when successful.

For example, a RL problem might be set up like this:
-
The user is looking for something (say, a restaurant) and has particular constraints in mind like the cuisine, price range, location, etc.
-
The bot asks questions and makes recommendations.
-
The bot receives a reward at the end of the conversation if it suggested something which meets all of the criteria, but the reward is reduced the longer the conversation takes.
This set-up gives you a well-posed problem to work with where you can make meaningful progress. Unfortunately, it doesn't always correlate with what you want in a commercial system.
In our experience, users don't really know what they want, and you often can't map their constraints to columns in a database. It's not a coincidence that the well-known success stories in reinforcement learning are in video and board games, where you know that the score is exactly the right reward.
The simplicity of reinforcement learning is both a strength and a weakness. Your system doesn't need to understand anything about its own behaviour, only which actions result in a reward.
On the other hand, your system might make dozens or hundreds of decisions before receiving a reward, and then has to figure out which of those decisions helped and which set it back. That requires a lot of experience.
I'm fully convinced that reinforcement learning is an important tool for the future of conversational AI. But right now it isn't the best approach for developers who want to build a functioning dialogue system.
There are a few practical, technical difficulties which make RL hard to apply, though all of these are being addressed by the research community.
-
RL is data hungry. You need thousands of conversations to learn even simple behaviours. And most RL algorithms can't learn from off-policy data, which means you can only learn from a conversation once, at the moment when you're having it. Though it's possible to do better.
-
Training with real humans in the loop giving rewards sounds great, but human evaluations are notoriously unreliable. Friends who competed in the Alexa prize tell me they were frustrated that some of their best conversations would get a 1 star review, while users would randomly award 5 stars to conversations that made no sense at all.
-
Training against a simulated user restricts you to problems that you can specify exactly as a reward function, which has issues as I mentioned in a previous post:
...if we train our system to optimise for maximum purchase value, we could end up with a very aggressive salesbot, or one which exploits weaknesses in our psychology.
We wanted Rasa Core to be useful to developers when they first try it. So step one couldn't be: "Implement a simulated user and a reward function which fully describe the behaviour you want." Nor could we say "go and annotate a few thousand real conversations and then come back".
Rasa Core had to leverage developers' existing domain knowledge to help them bootstrap from zero training data. That's what lead us to the interactive learning approach.
The Rasa Approach: Making applied research accessible to all developers
We've worked directly with hundreds of enterprises developing bots, and our experience is that flowcharts are useful for doing the initial design of a bot and describing a few of the happy paths, but you shouldn't take them literally and hard-code a bunch of rules. We've seen many times how this approach doesn't scale beyond simple conversations.
There's an asymmetry here which we want to exploit. On the one hand, it's totally obvious to anyone when a bot does the wrong thing. But on the other, reasoning about your state machine and hundreds of rules to figure out why it went wrong is really tricky. What if simply knowing what the bot should have done were enough?
With Rasa Core, you manually specify all of the things your bot can say and do. We call these actions. One action might be to greet the user, another might be to call an API, or query a database. Then you train a probabilistic model to predict which action to take given the history of a conversation.
That training can happen a few different ways. If you have a database of conversations you want to learn from, you can annotate them and run supervised learning. But very few people have a usable set of annotated conversations. What we recommend new users to do is to use interactive learning to bootstrap from zero data.
Bootstrapping Dialogue with Interactive Learning
In interactive learning mode, you provide step-by-step feedback on what your bot decided to do. It's kind of like reinforcement learning, but with feedback on every single step (rather than just at the end of the conversation).
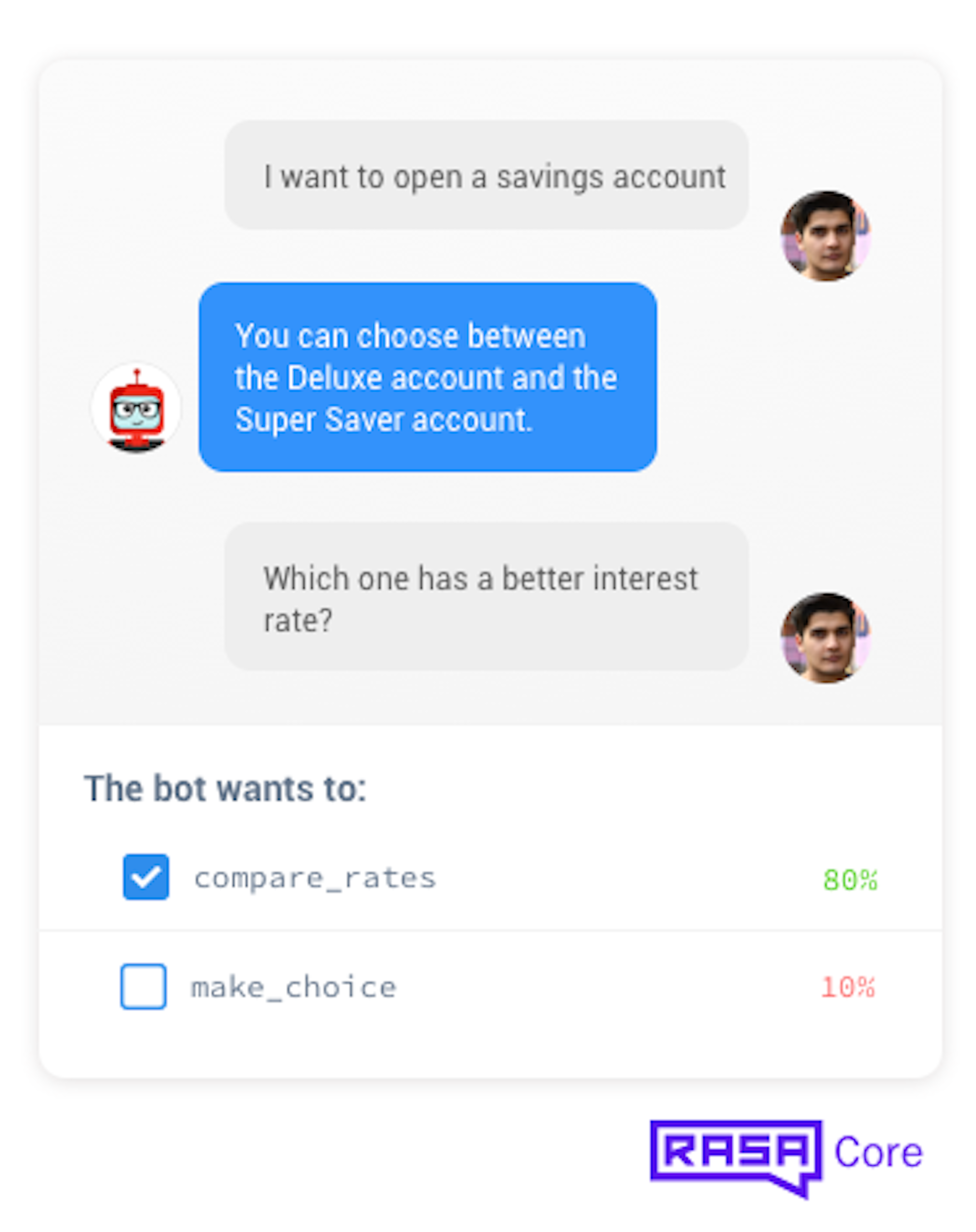
When your bot chooses the wrong action, you tell it what the right one would have been. The model updates itself immediately (so you are less likely to encounter the same mistake again) and once you finish, the conversation gets logged to a file and added to your training data.
You've instantly resolved an edge case, without staring at your code for ages figuring out what went wrong. And because you're providing step-by-step feedback, rather than a single reward at the end, you're teaching the system much more directly what's right and wrong.
In our experience, a couple of dozen short conversations are enough to get a first version of your system running.
What's Next
We've been working on Rasa Core for almost a year and a half already, and it's been running in production with our customers for close to a year. It's gone through about half a dozen complete re-thinks and re-implementations.
Over the last few months, we've had dozens of developers building with it as part of our early access programme. Thanks to all of them we've managed to simplify the documentation and the APIs to the point that we're ready to release it into the wild. It's released under a commercially-friendly license (just like Rasa NLU) so that people can build real stuff with it. We want Rasa Core to accelerate the arrival of great conversational software.
The Rasa Core repo is here.
If you'd like to work on these problems with us, you can join the Rasa team.
Interested in conversational software, natural language processing & building chatbots? Join the Rasa community on Gitter!
Thank you to Milica Gasic, Simon Willnauer, Matthaus Krzykowsky, and Alex Weidauer for your input on this post, and thank you to the Rasa team for making it all happen. You are world class, all of you.