



We can all relate to the frustrations of calling a business that uses an IVR system - "press 2 to talk to sales, press 3 to wait forever". Even "modern" systems that use speech recognition to navigate a tree still feel clunky and still often require a human to resolve the query in the end. So when Google unveiled Duplex, a great many people were blown away by a computer that could seamlessly and convincingly interact with a human over the phone. Afterwards, the internet was ablaze with commentary - that the Turing Test had been defeated, that morality was dead, and that we are all doomed. Regardless of the societal implications, the sheer impressiveness of the demo could not be ignored.
What's most exciting is that kind of natural, fluid conversation with a machine isn't confined to the halls of Google's research wing! One can use developer-friendly technologies like the open source Rasa Stack and services like Twilio to build an AI-powered phone agent right now. In this article I'm going to illustrate how you can build your own Duplex-like agent to handle phone calls autonomously. We're going to approach the problem at hand from the other direction - calling a business and talking with a machine (rather than a machine calling a business).
Overview
Before we continue, let's look at a prototype of a system I built with a colleague over the course of a few months for booking appointments with salons. It's simple, functional, and most importantly, it's AI-powered!
The diagram below describes the system used in the demo:
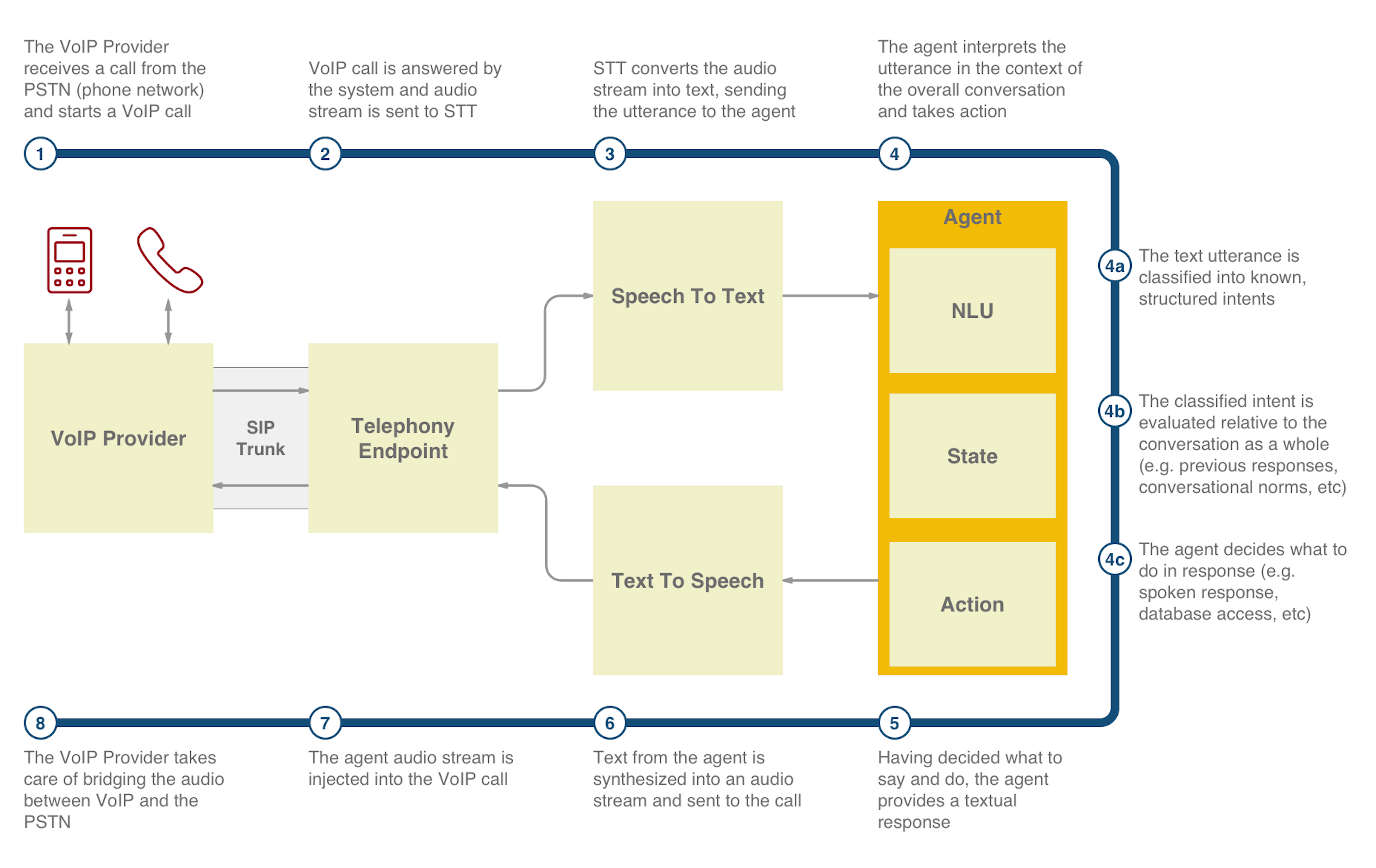
A system like this is comprised of 3 major parts:
- A means of connecting to the telephone network
- Systems for dealing with speech (speech-to-text and text-to-speech)
- An autonomous agent capable of carrying on a conversation and taking action
Telephony
Up until the last decade or so, if you wanted a machine to answer the phone, the telephone company and copper wires were involved. We don't want to maintain a closet full of hardware connected to the PSTN (the old-school copper wire telephone system), so instead we're going to leverage VoIP and the cloud for our needs.
In particular, Twilio offers an excellent service called Elastic SIP Trunking. You can think of a SIP trunk like a dedicated phone line over the internet. Twilio maintains hardware connected to the physical telephone network, and when a call comes in they initiate a VoIP call over the internet to your system. This is also true in reverse, when your system makes outbound calls. Many VoIP providers want you to buy individual trunks - meaning that if you paid for two trunks, your system can only have two active calls at any given time. Twilio, however, does not have this restriction - you simply pay for the time you use. This is the Elastic in Elastic SIP Trunking, and it also means that Twilio will scale alongside your system, no complex resource forecasting necessary.
For the demo above, I used two distinct software packages for handling the calls. The first package, Kamailio, serves as VoIP load balancer and router. It sits outside of our system's firewall and is where Twilio connects. Kamailio then routes the call inside the firewall to the second package, Asterisk. Asterisk is a Public Branch eXchange (PBX) platform which can perform all sorts of tasks - from hosting voicemail boxes to enabling conference calls to custom applications like ours. Asterisk handles controlling the call (answer, hangup, etc) and bridging audio to and from the speech subsystems.
Speech Transcription and Synthesis
So we've got a connection to the telephone system, now we need a way of dealing with the lingua franca of the telephone - audio. Over the last few years, machine learning techniques have yielded massive improvements in speech transcription and synthesis - we're in somewhat of a speech software renaissance. On the transcription side, companies like Google and Microsoft are claiming near-humanlevels of understanding, in a variety of environments. Meanwhile on the synthesis side, efforts like WaveNet and Tacotron are yielding more human-like results, even recreating the complex rhythms and inflections of native speakers (this is likely what the Duplex demo uses).
Building Autonomous Agents
The heart of our system is the agent, and the key to having a natural-sounding agent depends on it being able to have a coherent conversation. Trying to model a conversation using a simplistic tree-based approach simply won't cut it - we need a system that can react to curveballs and react gracefully. We need to employ some AI.
To tackle this problem, the team over at Rasa has built an awesome set of open source tools for building AI-powered agents. RasaNLU uses state of the art machine learning techniques to classify raw text into structured intents and extract entities (e.g. names, dates, quantities) from that text. Meanwhile, RasaCore uses a recurrent neural network (RNN) to build a probabilistic model of how a conversation should flow. This RNN-based model not only takes into account what the user just said, but it also "remembers" pertinent information to inform its response. This memory takes two forms: (1) previous turns in the conversation (e.g. "earlier the user said they wanted to reschedule, so move an appointment rather than creating a new one), and (2) facts (Rasa calls these slots) derived from the user's statements (e.g. "A haircut is the service we're talking about, and Carlos is the desired stylist").
Using Rasa removes the need to hard-code branches in the conversation or build rigid rulesets to drive conversational flow. Instead you provide Rasa (both NLU and Core) with sample data (the more the better) and the system will learn how to respond based on that training data - this is called supervised learning.
Below is an example of some NLU training data JSON:
[
...
{
"text": "I'd like to get a beard trim on Saturday.",
"intent": "schedule",
"entities": [
{
"start": 18,
"end": 28,
"value": "beard trim",
"entity": "service_name"
},
]
},
...
]
Here we've given an example phrase and how to classify it, including which part of the sentence represents the service the user wants. Rasa even supports out of the box some common classifiers for things like dates and times, so we don't have to annotate Saturday as an entity ourselves.
Similarly we provide conversation examples to train Rasa Core in markdown format:
## Schedule intent with valid service name
* schedule{"service_name":"beard trim"}
- action_service_lookup
- slot{"service_id": 12345}
- action_confirm_appointment
## Schedule intent with invalid service name
* schedule{"service_name":"jelly beans"}
- action_service_lookup
[note the lack of slot setting here compared to above]
- action_apologize_for_misunderstanding
- action_prompt_for_service
## Schedule intent with no service name
* schedule
- action_prompt_for_service
In this example, we've provided three conversation examples for how to respond to a schedule intent. With examples like this, the conversation engine will learn quite a few things:
- If a service name is provided (i.e. the
service_nameentity has been set on the intent), perform a lookup action (action_service_lookup). - If no service name is provided (i.e. the
service_nameentity has not been set), then prompt the user for a service name - If the service lookup succeeds (i.e. the
service_idslot is set as part ofaction_service_lookup), then confirm the appointment - If the service lookup fails (i.e. the
service_idslotis not set as part ofaction_service_lookup), then apologize and request the user state provide a service name
These examples are woefully simplistic, but they serve to illustrate the ease with which one can train their own conversational agent. Ultimately this training-based approach means that later on when your agent is presented with an input it has never seen before, it will make a best guess based on what it's learned - often to great effect. I encourage you to take a look at the Rasa Core overview - it does a much better job explaining why an ML approach to conversation flow is a game-changer.
The demo above used a hand-curated set of training data (e.g. list all of the ways you can think of to say "When are you open?") - approximately 1300 sentence examples for Rasa NLU training and a few hundred conversation examples for Rasa Core training. This training data was combined with custom-written software actions that did things like "look for an open appointment slot" or "confirm an appointment slot", and were exposed to Rasa for use in the conversation. The agent would decide which of these actions to run in response to user input, and the response from those actions were used to inform future responses (e.g. whether or not an appointment slot was found at the requested time).
Putting it all together
We've covered the 3 major pieces of the system - telephony, speech, and the agent. Let's put it all together:
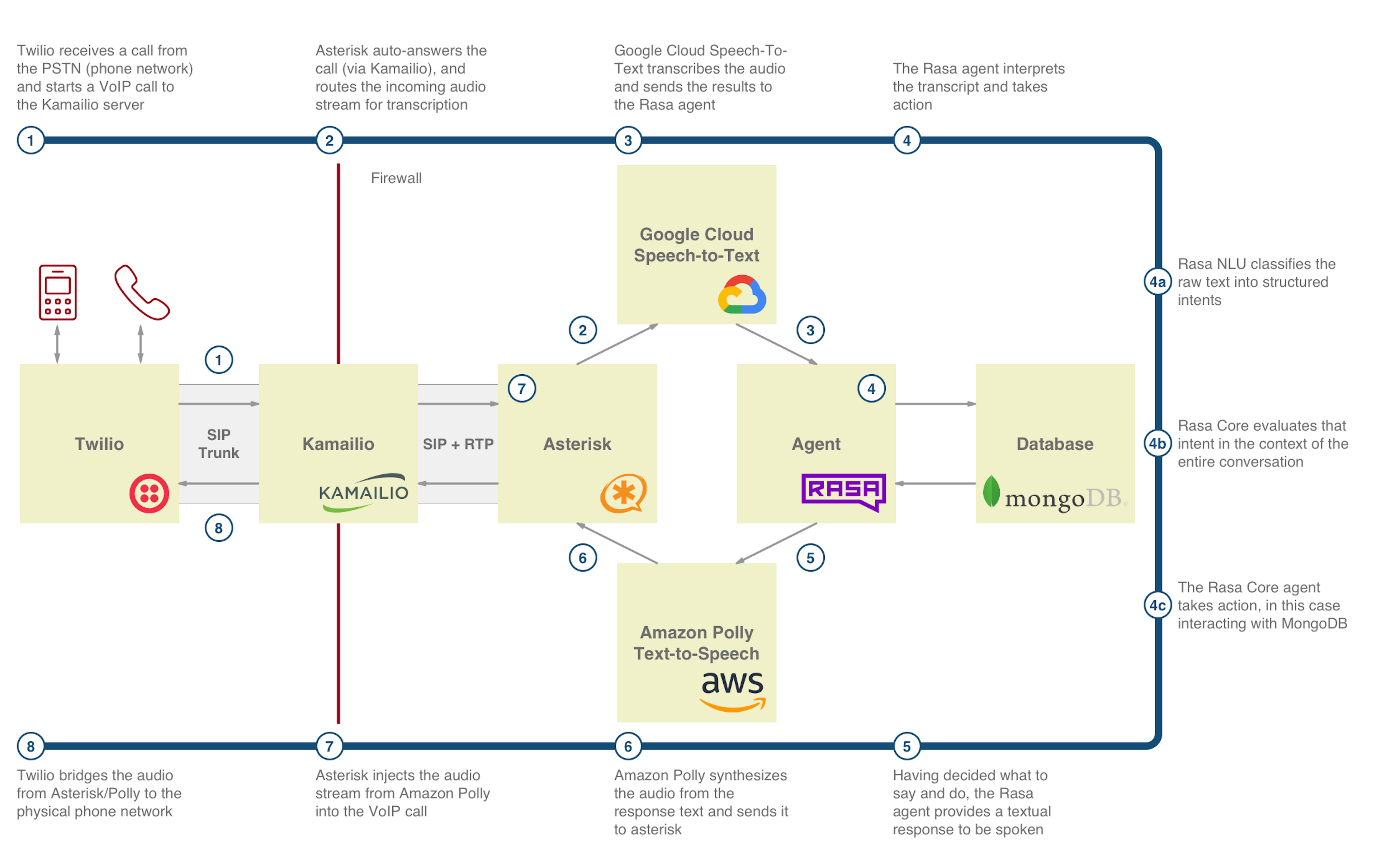
This rough architecture diagram describes the structure of the demo above. It ran on a Kubernetes cluster managed by Google Kubernetes Engine, in a heavily microservice-oriented architecture. Each box was more or less one Kubernetes Pod (in reality there were a couple of glue pods that were omitted here for brevity). The custom software was written in a combination of Go, Python, and Node.js, based on the task at hand.
Conclusion
We're in a period of human-computer interaction history where the widespread availability of machine learning allows us to build unprecedented new interactions. You don't have to be an ML researcher to get in on the action, either - software like the Rasa Stack brings state-of-the-art research into a usable product. Pair that with an awesome communication stack from Twilio, and your software can interact with the world in entirely new ways.
Appendix
Resources
As noted above, there are a number of speech systems out in the wild, here are a few links to get you started, though this is by no means a comprehensive list.
Speech-To-Text Systems
- Google Cloud Speech-To-Text
- Amazon Transcribe
- IBM Watson
- Microsoft Azure Speech-To-Text
- AssemblyAI
- Mozilla DeepSpeech + Common Voice
Text-To-Speech Systems
- Google Cloud Text-To-Speech
- Amazon Polly
- IBM Watson
- Microsoft Azure Text-To-Speech
- One of the Open Source Tacotron implementations
About the Author
Josh Converse is the founder of Dynamic Offset, a boutique consulting firm specializing in building great customer experiences through mobile, web, and conversational interfaces. Prior to consulting he was a tech lead at both Google and Apple. Drop a line and say hi - hello@dynamicoffset.io!