

March 9th, 2020
Introducing DIET: state-of-the-art architecture that outperforms fine-tuning BERT and is 6X faster to train
Mady Mantha

At Rasa, we're excited about making cutting-edge machine learning technology accessible in a developer-friendly workflow. With Rasa 1.8, our research team is releasing a new state-of-the-art lightweight, multitask transformer architecture for NLU: Dual Intent and Entity Transformer (DIET).
In this post, we'll talk about DIET's features and how you can use it in Rasa to achieve more accuracy than anything we had before. We're releasing an academic paper that demonstrates that this new architecture improves upon the current state of the art, outperforms fine-tuning BERT, and is six times faster to train.
What is DIET
DIET is a multi-task transformer architecture that handles both intent classification and entity recognition together. It provides the ability to plug and play various pre-trained embeddings like BERT, GloVe, ConveRT, and so on. In our experiments, there isn't a single set of embeddings that is consistently best across different datasets. A modular architecture, therefore, is especially important.
Why use DIET
Large-scale pre-trained language models aren't ideal for developers building conversational AI applications.
DIET is different because it:
- Is a modular architecture that fits into a typical software development workflow
- Parallels large-scale pre-trained language models in accuracy and performance
- Improves upon current state of the art and is 6X faster to train
Large-scale pre-trained language models have shown promising results on language understanding benchmarks like GLUE and SuperGLUE, and in particular, shown considerable improvements over other pre-training methods like GloVe and supervised approaches. Since these embeddings are trained on large-scale natural language text corpora, they're well equipped to generalize across tasks.
Last year, I helped build a help desk assistant that automated conversations and repeatable IT processes. We integrated the assistant with BERT, because at the time, BERT and other big language models achieved top performance on a variety of NLP tasks. While it helped resolve some issues, BERT also presented its own challenges; it was really slow and needed a GPU to train.
Large-scale models tend to be compute-intensive, training time-intensive, and present pragmatic challenges for software developers that want to build robust AI assistants that can be quickly trained and iterated upon. Moreover, if you're building multilingual AI assistants, it's important to achieve high level performance without large-scale pre-training as most pre-trained models are trained on English text.
Prior to DIET, Rasa's NLU pipeline used a bag of words model where there was one feature vector per user message. Though this is a fast, tough-to-beat baseline, we're now going beyond it.
DIET uses a sequence model that takes word order into account, thereby offering better performance. It's also a more compact model with a plug-and-play, modular architecture. For instance, you can use DIET to do both intent classification and entity extraction; you can also perform a single task, for example, configure it to turn off intent classification and train it just for entity extraction.
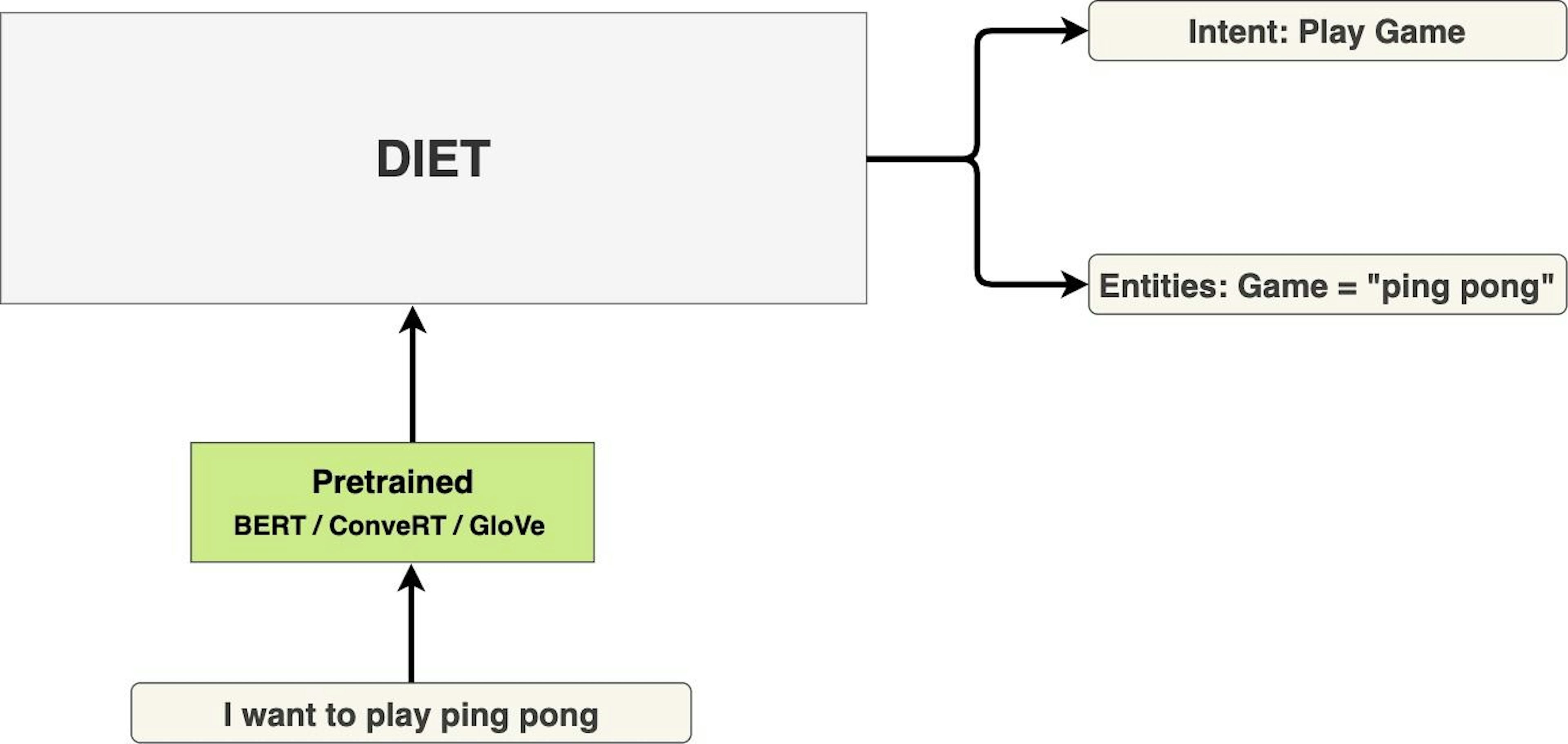
Additionally, DIET is not only considerably faster to train but also parallels large-scale pre-trained language models in performance. It outperforms fine-tuning BERT and improves upon the current state of the art on a complex NLU dataset. Achieving state-of-the-art accuracy may no longer mean sacrificing efficiency.
How to use DIET
To prepare for DIET, we upgraded to Tensorflow 2.1. TF 2 makes it easier to build and train models, and intuitively debug issues.
In order to do intent classification and entity extraction using the new DIET architecture, add the DIETClassifier component to the NLU pipeline configuration file.
Here's the configuration file that's created when you invoke rasa init.
language: en
pipeline:
- name: WhitespaceTokenizer
- name: RegexFeaturizer
- name: LexicalSyntacticFeaturizer
- name: CountVectorsFeaturizer
- name: CountVectorsFeaturizer
analyzer: "char_wb"
min_ngram: 1
max_ngram: 4
- name: DIETClassifier
epochs: 100
- name: EntitySynonymMapper
- name: ResponseSelector
epochs: 100
Let's take a look at the DietClassifier and its dependencies. The DIETClassifier depends on two classes of featurizers-dense featurizers and sparse featurizers. Featurization is the process of converting user messages into numerical vectors. The key difference between sparse and dense featurizers is that sparse featurizers compact feature vectors that contain mostly zeroes into a memory efficient structure. If you'd like to learn more about using sparse features, check out this post.
The ConveRTFeaturizer is an example of a dense featurizer that uses the ConveRT model. The LanguageModelFeaturizer is another example of a dense featurizer that uses a pre-trained language model like BERT.
The CountVectorsFeaturizer is an example of a sparse featurizer. It can be configured to use word or character n-grams. The LexicalSyntacticFeaturizer is another example of a sparse featurizer. It creates features for entity extraction using a sliding window over each token in a given user message. The LexicalSyntacticFeaturizer component can be configured to specify the type of lexical and syntactic features to extract.
Also, DIETClassifer can be fine-tuned using various hyperparameters. For example, you can configure the neural network's architecture by specifying the size of the transformer, the number of transformer layers, the number of attention heads to use and so on.
If you're upgrading to Rasa 1.8, check out the migration guide for instructions. As always, we encourage everyone to define their own pipeline by listing the names of the components you want to use.
Next Steps
We're really excited about DIET, a new multi-task transformer architecture we invented. We released it for two reasons: building performant AI assistants doesn't always require large-scale pre-trained language models, and we wanted to provide a flexible, plug-and-play architecture for developers. DIET advances the current state of the art, outperforms fine tuning BERT, and is six times faster to train.
We're releasing a paper on it soon. Until then, check out more information on DIET and watch this video on how it works. Try it out and please share your results in the forum. Keep up with the new developments by following Rasa on Twitter.