


AI assistants have to fulfill two tasks: understanding the user and giving the correct responses. The Rasa Stack tackles these tasks with the natural language understanding component Rasa NLU and the dialogue management component Rasa Core. Based on our work with the Rasa community and customers from all over the world, we are now sharing our best practices and recommendations how to custom-tailor Rasa NLU for your individual contextual AI assistant. To be able to give you deep insights in every component we decided to split this in a series of three consecutive blog posts:
- Part 1: Intent Recognition - How to better understand your users
- Part 2: Entity Extraction - Choose the right extractor for each entity
- Part 3: Hyperparameters - How to select and optimize them
What makes NLP for contextual AI assistants so special that we decided to cover this in a series of three blog posts? The reason is that contextual AI assistants can be highly domain specific which means they have to be custom-tailored for your use case just as websites are custom-tailored for each company. Rasa NLU provides this full customizability by processing user messages in a so called pipeline. A pipeline defines different components which process a user message sequentially and ultimately lead to the classification of user messages into intents and the extraction of entities. Check out our latest blog post on custom components if you want to learn more about how the pipeline works and how to implement your own NLU component.
This blog post marks the start of this three-piece series and will provide you with in-depth information on the NLU components which are responsible for understanding your users, including
- Which intent classification component should you use for your project
- How to tackle common problems: lack of training data, out-of-vocabulary words, robust classification of similar intents, and skewed datasets
Intents: What Does the User Say
Rasa uses the concept of intents to describe how user messages should be categorized. Rasa NLU will classify the user messages into one or also multiple user intents. The two components between which you can choose are:
- Pretrained Embeddings (Intent_classifier_sklearn)
- Supervised Embeddings (Intent_classifier_tensorflow_embedding)
Pretrained Embeddings: Intent Classifier Sklearn
This classifier uses the spaCy library to load pretrained language models which then are used to represent each word in the user message as word embedding. _Word embedding_s are vector representations of words, meaning each word is converted to a dense numeric vector. Word embeddings capture semantic and syntactic aspects of words. This means that similar words should be represented by similar vectors. If you want you can learn more about it in the original word2vec paper.
Word embeddings are specific for the language they were trained on. Hence, you have to choose different models depending on the language which you are using. See this overview of available spaCy language models. If you want you can also use different word embeddings, e.g. Facebook's fastText embeddings. To do so follow the spaCy guide here to convert the embeddings to a compatible spaCy model and then link the converted model to the language of your choice (e.g. en) with python -m spacy link <converted model> <language code>.
Rasa NLU takes the average of all word embeddings within a message, and then performs a gridsearch to find the best parameters for the support vector classifier which classifies the averaged embeddings into the different intents. The gridsearch trains multiple support vector classifiers with different parameter configurations and then selects the best configuration based on the test results.
When You Should Use This Component:
When you are using pretrained word embeddings you can benefit from the recent research advances in training more powerful and meaningful word embeddings. Since the embeddings are already trained, the SVM requires only little training to make confident intent predictions.This makes this classifier the perfect fit when you are starting your contextual AI assistant project. Even if you have only small amounts of training data, which is usual at this point, you will get robust classification results. Since the training does not start from scratch, the training will also be blazing fast which gives you short iteration times.
Unfortunately good word embeddings are not available for all languages since they are mostly trained on public available datasets which are mostly English. Also they do not cover domain specific words, like product names or acronyms. In this case it would be better to train your own word embeddings with the supervised embeddings classifier.
Supervised Embeddings: Intent Classifier TensorFlow Embedding
The intent classifier intent_classifier_tensorflow_embedding was developed by Rasa and is inspired by Facebook's starspace paper. Instead of using pretrained embeddings and training a classifier on top of that, it trains word embeddings from scratch. It is typically used with the intent_featurizer_count_vectors component which counts how often distinct words of your training data appear in a message and provides that as input for the intent classifier. In the illustration below you can see how the count vectors would differ for the sentences My bot is the best bot and My bot is great, e.g. bot appears twice in My bot is the best bot. Instead of using word token counts, you can also use ngram counts by changing the analyzer property of the intent_featurizer_count_vectors component to char. This makes the intent classification more robust against typos, but also increases the training time.

Furthermore, another count vector is created for the intent label. In contrast to the classifier with pretrained word embeddings the tensorflow embedding classifier also supports messages with multiple intents (e.g. if your user says Hi, how is the weather? the message could have the intents greet and ask_weather) which means the count vector is not necessarily one-hot encoded. The classifier learns separate embeddings for feature and intent vectors. Both embeddings have the same dimensions, which makes it possible to measure the vector distance between the embedded features and the embedded intent labels using cosine similarity. During the training, the cosine similarity between user messages and associated intent labels is maximized.
When You Should Use This Component:
As this classifier trains word embeddings from scratch, it needs more training data than the classifier which uses pretrained embeddings to generalize well. However, as it is trained on your training data, it adapts to your domain specific messages as there are e.g. no missing word embeddings. Also it is inherently language independent and you are not reliant on good word embeddings for a certain language. Another great feature of this classifier is that it supports messages with multiple intents as described above. In general this makes it a very flexible classifier for advanced use cases.
Note that in some languages (e.g. Chinese) it is not possible to use the default approach of Rasa NLU to split sentences into words by using whitespace (spaces, blanks) as separator. In this case you have to use a different tokenizer component (e.g. Rasa provides the Jieba tokenizer for Chinese).
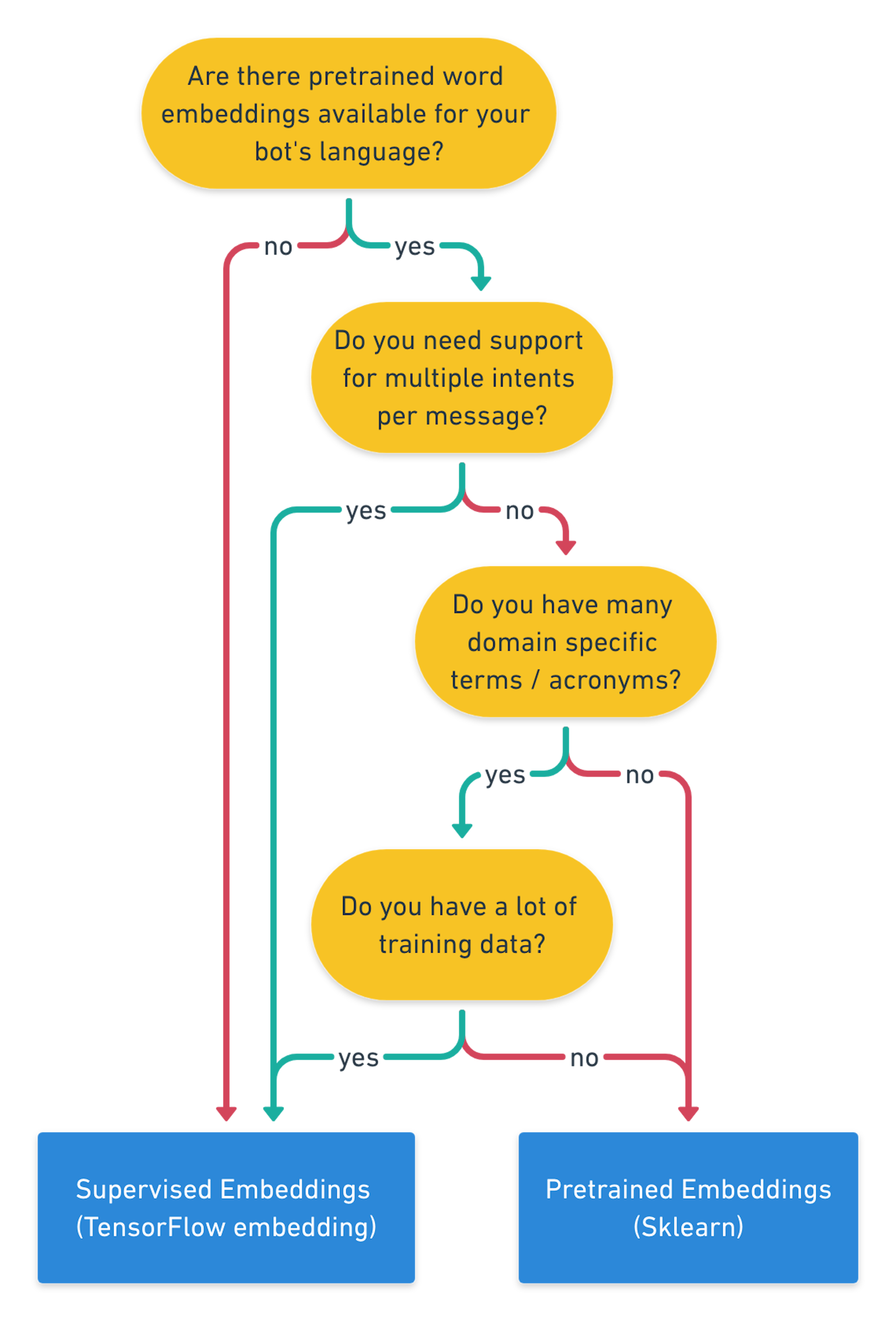
If you are still not sure which component is best for your contextual AI assistant, use the flow chart below to get a quick rule of thumb decision.
Common Problems
Lack of training data
When the bot is actually used by users you will have plenty of conversational data to pick your training examples from. However, especially in the beginning it is a common problem that you have little to none training data and the accuracies of your intent classifications are low. A often used approach to overcome this issue is to use the data generation tool chatito developed by Rodrigo Pimentel. Generating sentences out of predefined word blocks can give you a large dataset quickly. Avoid using data generation tools too much, as your model may overfit on your generated sentence structures. We strongly recommend you to use data from your real users. Another option to get more training data is to crowdsource it, e.g. with Amazon Mechanical Turk (mturk). From our experience the interactive learning feature of Rasa Core is also very helpful to get new Core and NLU training data: when actually speaking to the bot, you automatically frame your messages differently than when your are thinking of potential examples in an isolated setting.
Out-of-Vocabulary Words
Inevitably, users will use words which your trained model has no word embeddings for, e.g. by making typos or simply using words you have not thought of. In case you are using pretrained word embeddings there is not much what you can do except trying language models which were trained on larger corpora. In case you are training the embeddings from scratch using the intent_classifier_tensorflow_embedding classifier you have two options: either include more training data or add examples which include the OOV_token (out-of-vocabulary token). You can do the latter by configuring the OOV_token parameter of the intent_classifier_tensorflow_embedding component, e.g. by setting it to <OOV>, and adding examples which include the <OOV> token (My <OOV> is Sara). By doing that the classifier learns to deal with messages which include unseen words.
Similar Intents
When intents are very similar, it is harder to distinguish them. What sounds obvious, often is forgotten when creating intents. Imagine the case, where a user provides their name or gives you a date. Intuitively you might create an intent provide_name for the message It is Sara and an intent provide_date for the message It is on Monday. However, from an NLU perspective these messages are very similar except for their entities. For this reason it would be better to create an intent inform which unifies provide_name and provide_date. In your Rasa Core stories you can then select the different story paths, depending on which entity Rasa NLU extracted.
Skewed data
You should always aim to maintain a rough balance of the number of examples per intent. However, sometimes intents (e.g. the inform intent from the example above) can outgrow the training examples of other intents. While in general more data helps to achieve better accuracies, a strong imbalance can lead to a biased classifier which in turn affects the accuracies negatively. Hyperparameter optimization, which will be covered in parth three of this series, can help you to cushion the negative effects, but the by far best solution is to reestablish a balanced dataset.
Summary
This blog article reflects our best practices and recommendations based on our daily work with Rasa to perfectly custom-tailor the NLU intent recognition to your individual requirements. Whether you have just started your contextual AI assistant project, need blazing fast training times, or want to train word embeddings from scratch: Rasa NLU gives you the full customizability to do so. After reading part 1 our Rasa NLU in Depth series you now should be confident about the decision which component you want to choose for intent classification and how to configure it.
What about entity recognition? The upcoming part 2 of this series will give you some first-hand advice which entity extractor components to choose, and how to tackle problems like address extraction or fuzzy entity recognition.
What can you do in the meanwhile?