


Welcome back to part 2 of the Rasa NLU in Depth series. In this three-piece blog post series we share our best practices and experiences about Rasa NLU which we gained in our work with community and customers all over the world. Part 1 of our series covered the different intent classification components of Rasa NLU and which of these components are the best fit for your individual contextual AI assistant.
Understanding the user's intent is only part of the problem. It is equally important to extract relevant information from a user's message, such as dates and addresses. This process of extracting the different required pieces of information is called entity recognition. Depending on which entities you want to extract, our open-source framework Rasa NLU provides different components. Continuing our Rasa NLU in Depth series, this blog post will explain all available options and best practices in detail, including:
- Which entity extraction component to use for which entity type
- How to tackle common problems: fuzzy entities, extracting addresses, and mapping of extracted entities
Extracting Entities
As open-source framework, Rasa NLU puts a special focus on full customizability. As result Rasa NLU provides you with several entity recognition components, which are able to target your custom requirements:
- Entity recognition with SpaCy language models: ner_spacy
- Rule based entity recognition using Facebook's Duckling: ner_http_duckling
- Training an extractor for custom entities: ner_crf
SpaCy
The spaCy library offers pretrained entity extractors. As with the word embeddings, only certain languages are supported. If your language is supported, the component ner_spacy is the recommended option to recognise entities like organization names, people's names, or places. You can try out the recognition in the interactive demo of spaCy.
Duckling
Duckling is a rule-based entity extraction library developed by Facebook. If you want to extract any number related information, e.g. amounts of money, dates, distances, or durations, it is the tool of choice. Duckling was implemented in Haskell and is not well supported by Python libraries. To communicate with Duckling, Rasa NLU uses the REST interface of Duckling. Therefore, you have to run a Duckling server when including the ner_duckling_http component into your NLU pipeline. The easiest way to run the server, is to use our provided docker image rasa/rasa_duckling and run the server with docker run -p 8000:8000 rasa/rasa_duckling.
NER_CRF
Neither ner_spacy nor ner_duckling require you to annotate any of your training data, since they are either using pretrained classifiers (spaCy) or rule-based approaches (Duckling). The ner_crf component trains a conditional random field which is then used to tag entities in the user messages. Since this component is trained from scratch as part of the NLU pipeline you have to annotate your training data yourself. This is an example from our documentation on how to do so:
## intent:check_balance- what is my balance <!-- no entity -->- how much do I have on my [savings](source_account) <!-- entity "source_account" has value "savings" -->Use ner_crf whenever you cannot use a rule-based or a pretrained component. Since this component is trained from scratch be careful how you annotate your training data:
- Provide enough examples (> 20) per entity so that the conditional random field can generalize and pick up the data
- Annotate the training examples everywhere in your training data
(even if the entity might not be relevant for the intent)
Regular Expressions / Lookup Tables
To support the entity extraction of the ner_crf component, you can also use regular expressions or lookup tables. Regular expressions match certain hardcoded patterns, e.g. [0-9]5 would match 5 digit zip codes. Lookup tables are useful when your entity has a predefined set of values. The entity country can for example only have 195 different values. To use regular expressions and / or lookup tables add the intent_entity_featurizer_regex component before the ner_crf component in your pipeline. Then annotate your training data as described in the documentation.
## regex:zipcode- [0-9]{5}
## lookup:currencies <!-- lookup table list -->- Yen- USD- Euro
## lookup:additional_currencies <!-- no list to specify lookup table file -->path/to/currencies.txtRegular expressions and lookup tables are adding additional features to ner_crf which mark whether a word was matched by a regular expression or lookup table entry. As it is one feature of many, the component ner_crf can still ignore an entity although it was matched, however in general ner_crf develops a bias for these features. Note that this can also stop the conditional random field from generalizing: if all entity examples in your training data are matched by a regular expression, the conditional random field will learn to focus on the regular expression feature and ignore the other features. If you then have a message with a certain entity which is not matched by the regular expression, ner_crf will probably not be able to detect it. Especially the use of lookup tables makes ner_crf prone for overfitting.
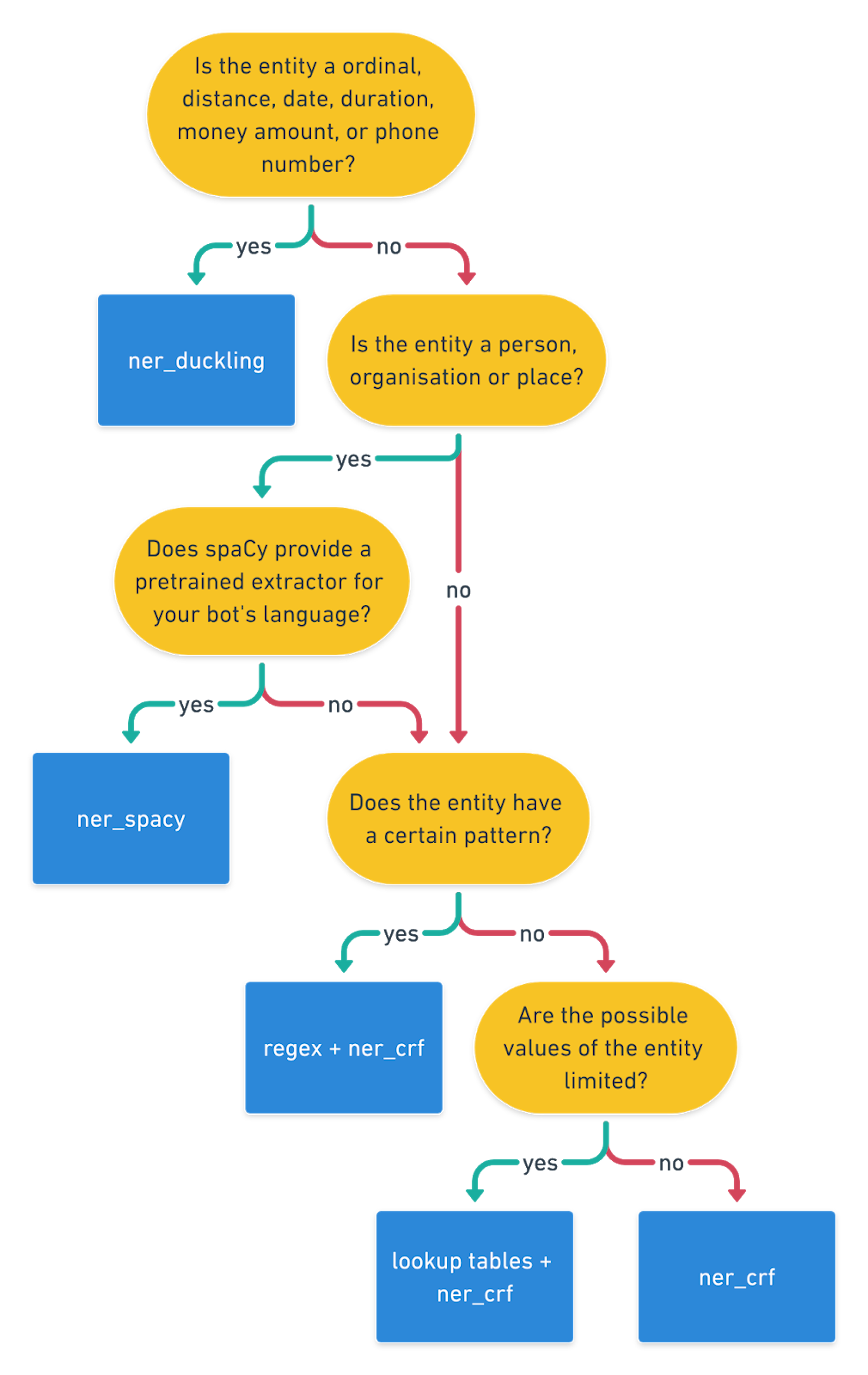
If you are still not sure which entity extraction component is best for your contextual AI assistant, use the flowchart below to get a quick rule of thumb decision:
Common Problems
Entities Are Not Generalizing
If the extraction of your entities does not generalize to unseen values of this entity, there can be two reasons: lack of training data and / or an overfitting ner_crf component. If you take heavy use of regular expressions or lookup table features, try training your model without them to see if they make the model overfit. Otherwise, add more examples for your entities which your model can learn from.
Extracting Addresses
If you want to extract addresses we recommend to use the ner_crf component with lookup tables. As described in our blog article on lookup tables you can generate lookup tables from sources such as openaddresses.io and use generated lists of cities and countries to support the entity extraction process of ner_crf.
Map Extracted Entity to Different Value
Sometimes extracted entities have different representations for the same value. If you are extracting countries for example, U.S., USA, United States of America, all refer to the same country. If you want to map them to one specify value, you can use the component ner_synonyms to map extracted entities to different values. In your training data, you can specify synonyms either inline
## intent:check_balance- how much do I have on my [savings account](source_account:savings) <!-- synonyms, method 1 -->or as separate section:
## synonym:savings <!-- synonyms, method 2 -->- pink pigSummary
Part 2 of our Rasa NLU in Depth series covered our best practices and recommendations to make perfect use of the different entity extraction components of Rasa NLU. By combining pretrained extractors, rule-based approaches, and training your own extractor wherever needed, you have a powerful toolset at hand to extract the information which your user is passing to your contextual AI assistant. After reading part 2 of our Rasa NLU in Depth series you now should be confident about the decision which components you want to choose for entity recognition, how to configure and even combine them.
You already know how to build the perfect NLU pipeline for your contextual AI assistant, but you now want to take it to the next level? Learn about hyperparameter optimization in the final part of your Rasa NLU in Depth series.
What can you do in the meanwhile?
- Share your NLU tweaking experiences with the community in the Rasa forum
- Recap part 1 of the Rasa NLU in Depth series: intent recognition
- Design your own NLU pipeline component
- Learn to fail gracefully