


Welcome to the grand finale of the Rasa NLU in Depth series 🎉
In this three-piece blog post series we shared our best practices and experiences about the open-source framework Rasa NLU which we gained in our work with the Rasa community and customers all over the world.
A quick recap what we have covered so far:
- How to understand your user - Intent Classification with Rasa NLU
- Extracting information from user messages - Entity Recognition
Part 1 and part 2 of this series give you all the tools and knowledge to select the perfect NLU pipeline for your contextual AI assistant. This last part of the series will be all about fine-tuning the configuration of the Rasa NLU pipeline to get the maximum performance. As part of this blog post we will cover:
- How to run hyperparameter optimization at scale with Rasa NLU
- Which hyperparameters give the biggest boost when fine-tuning them
Hyperparameter Optimization
In part 1 and 2 of the Rasa NLU in Depth series we explained which NLU components are the best for your individual use case and how to deal with potential problems. Choosing the right components is key to the success of your contextual AI assistant. However, if you want to go the extra mile and get the best out of the components, you have to tweak the configuration parameters (also called hyperparameters) of the single components. Finding the best configuration is done by training different models with different parameter configurations, and evaluating them on a validation set. The hyperparameters which lead to the best evaluation score are the result of the hyperparameter search. As there are quite many parameters for the components and the model trainings are computational intense, we will show you how to utilize Docker containers so that you can conveniently spread out your hyperparameter search to multiple machines.
Defining the Search Space
To get started, clone the rasaHQ/nlu-hyperopt repository. Define a template for your NLU pipeline which you want to tweak in data/template_config.yml. Replace the parameters which you want to optimize with their variable name in curly brackets, e.g.:
language: enpipeline:- name: "intent_featurizer_count_vectors"- name: "intent_classifier_tensorflow_embedding" epochs: {epochs}In the example above we define a NLU pipeline for intent classification with the intent_classifier_tensorflow_embedding classifier. During the hyperparameter search we will try to find the optimal number of training epochs.
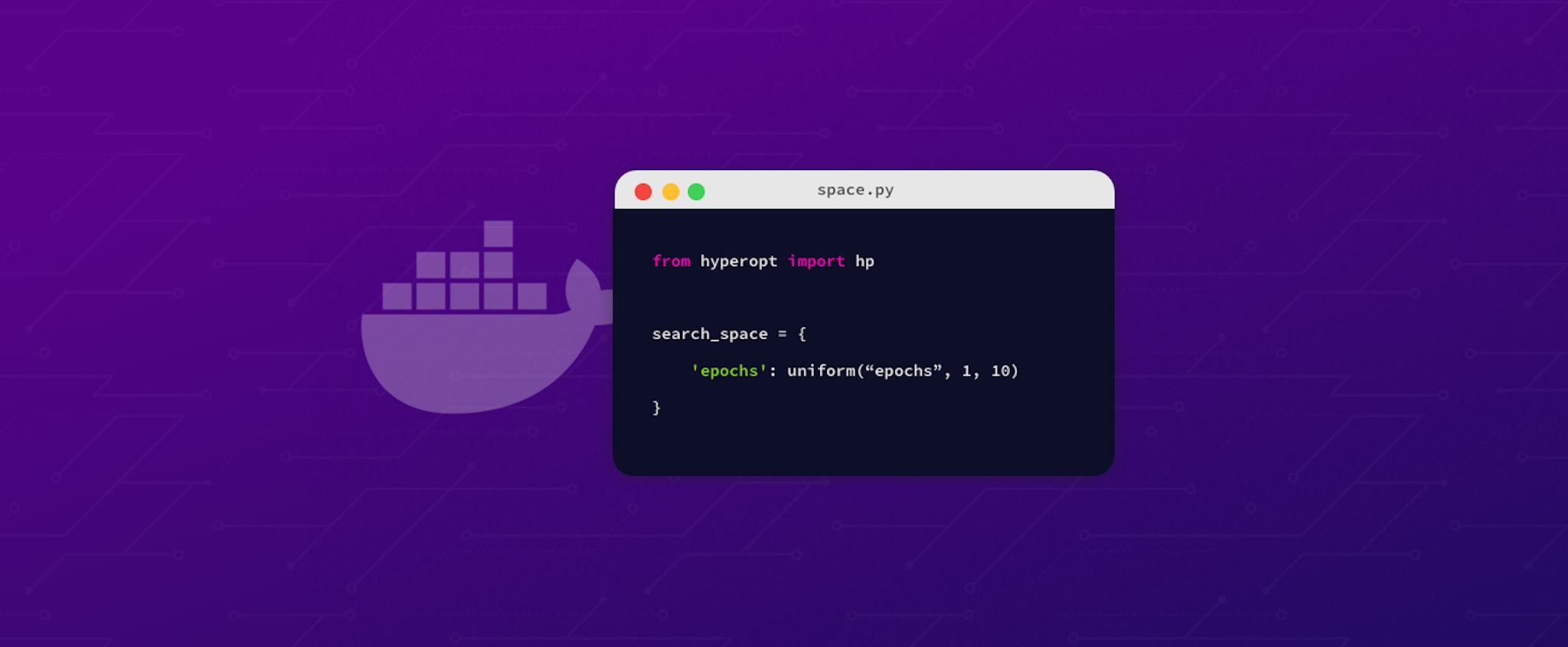
The next step is to define the range of the parameters you want to evaluate with your NLU model. Adapt the file nlu_hyperopt/space.py according to the hyperparameters which you want to optimize, e.g:
from hyperopt import hp
search_space = { 'epochs': hp.uniform("epochs", 1, 10)}With the given search space, the model would be trained with different numbers of epochs, whereby the number of epochs is in the range between 1 and 10. You can also choose among other distributions to pull your hyperparameter candidates from. See the hyperopt docs for more information.
There are so many hyperparameters for the components - where should I start? Since the intent_classifier_sklearn for pretrained word embeddings already performs a grid search during the training, the hyperparameter optimization will give you the most additional benefit if you train your own word embeddings using the intent_classifier_tensorflow_embedding. Important hyperparameters for this components are the one from the featurizer component intent_featurizer_count_vectors and the classifier itself. For the component intent_featurizer_count_vectors we recommend you to play around with min_df, max_df, and max_features. Check out the Sklearn documentation for their detailed description.
The tensorflow classifier has quite a number of parameters. We suggest to start adjusting the dimensions of your trained embeddings (embed_dim) and the number and size of the used hidden layers (hidden_layers_sizes_a and hidden_layers_sizes_b). For all three parameters, higher values should give you more accuracy, but also might lead to overfitting.
Configuring the Hyperparameter Search
Finally, configure your experiment. This is done through environment variables. If you want to run the hyperparameter search sequentially or without Docker you can ignore the settings for the mongo database. The configuration options are described in greater detail in the readme file of the repository, so we will focus on the most important ones for the sake of conciseness.
MAX_EVALS
This parameter describes how many evaluations you want to run. If the number of parameter combinations (aka search space) is small, you may choose a smaller number. If the search space is very large, you have to perform more evaluations to get a sufficient coverage of the search space.
TARGET_METRIC
This variable defines the metric which is used to compare the trained models. You can choose between:
- f1_score: Searches for the model which has the highest f1 score on the evaluation dataset.
- accuracy: Searches for the model which has the highest accuracy on the evaluation dataset.
- precision: Searches for the model which has the highest precision on the evaluation dataset.
- threshold_loss: While the other metrics count a prediction as correct when it has the highest confidence value of all intents, this loss function only counts a prediction as correct if the prediction is correct and its confidence value is above a given threshold. This accounts for the use of fallback policies to disambiguate predictions with low confidence values. You can use the parameter ABOVE_BELOW_WEIGHT to specify whether you want to penalize incorrect predictions above the threshold more or rather correct predictions below the threshold.
Then add a training set which is used to train the models and a evaluationset which is used to evaluate the models. Specify them by putting the training data in data/train.md the evaluation data in data/validation.md.
Running it
Eventually it is time to run the hyperparameter search. You can either run the hyperparameter search locally without Docker (it will then run sequentially) or use Docker containers.
If you want to run it locally, install the required dependencies with pip install -r requirements.txt and run the experiment with python -m nlu_hyperopt.app.
If you want to run it with Docker run docker-compose up -d --scale hyperopt-worker=<number of concurrent workers>. This will build a Docker image including your data, search space and template configuration and use a mongo database to run the experiment in parallel. Of course you can also run this experiment on a cluster, and distribute the workers on different machines. Most cluster orchestration tools such as Kubernetes are also able to parse the given docker-compose file.
When the evaluation is finished the best pipeline configuration will be printed in the logs, e.g.:
INFO:__main__:The best configuration is:
language: en
pipeline:
- name: "intent_featurizer_count_vectors"
- name: "intent_classifier_tensorflow_embedding"
epochs: 8.0
If you ran the hyperparameter search with Docker and the mongo database, all evaluation results are stored in the mongo database. Execute docker-compose exec mongodb mongo in your command line to jump into the mongo container and have a closer look at the evaluation results. The following command e.g. prints the evaluation results in descending order:
db.jobs.find({"exp_key" : "default-experiment", "result.loss":{$exists: 1}}).sort({"result.loss": 1})
Summary
This blog post was the last one in our three-piece Rasa NLU in Depth series to reflect our best practices and recommendations to perfectly custom-tailor the NLU pipeline to your requirements. You now should be a Rasa NLU expert, and confident about selecting and customizing the perfect Rasa NLU pipeline for your individual contextual AI assistant. Congratulations! 🎉🤖
Do you have some insights about the Rasa NLU pipeline which you want to share with us or want to share your fine-tuning results with others? Check out the thread in the forum and discuss your ideas with the other Rasa experts in our community.