



The Rasa Masterclass is a weekly video series that takes viewers through the process of building an AI assistant, all the way from idea to production. Hosted by Head of Developer Relations Justina Petraityte, each episode focuses on a key concept of building sophisticated AI assistants with Rasa and applies those learnings to a hands-on project. At the end of the series, viewers will have built a fully-functioning AI assistant that can locate medical facilities in US cities.
To supplement the video content, we'll be releasing blog posts to summarize each episode. You can follow along with these posts as you watch to reinforce your understanding, or you can use them as a quick reference. We'll also include links to additional resources you can use to help you along your journey.
Introduction
In Episode 2 of the Rasa Masterclass, we focus on generating NLU training data, including:
- The basics of conversation design
- How to format your assistant's NLU training data
- How to define the intents and entities your assistant can understand
What We're Building
Before we get into the details of generating NLU training data, let's briefly discuss what we'll be building over the course of the Masterclass series. The Medicare Locator is an AI assistant that uses the Medicare.gov API to locate hospitals, nursing homes, and home health agencies in US cities. We'll be building this assistant from beginning to end throughout the series. When we're finished, the assistant will be able to answer requests like "Give me the address of a hospital in San Francisco."
In this episode, we'll cover the basics of conversational design and generating training data using the Medicare Locator as an example.
Conversation Design
The first step to building a successful contextual assistant is planning the types of conversations your assistant will be able to have, a process known as conversation design. Conversation design should start with three important planning steps to ensure your assistant will meet the needs of your users:
- Asking who your users are
- Understanding the assistant's purpose
- Documenting the most typical conversations users will have with the assistant
Gathering possible questions
Once you've considered who your users are and the intended purpose of your assistant, start assessing what you already know about your potential audience. The goal is to begin compiling a list of common questions your users are likely to ask your assistant.
Do this by:
- Leveraging the knowledge of domain experts
- Looking at common search queries on your website
- Asking your customer service team about their most common requests
If you don't have access to historical conversation data, you can use the Wizard of Oz approach to gather information. This technique gets its name from a classic scene in the film The Wizard of Oz, where the "wizard" is revealed to be a man behind a curtain. When you use the Wizard of Oz approach, you are the man behind the curtain, so to speak. Recruit a volunteer to play the part of your user while you play the role of the bot. Simulate a human-bot chat interaction and record the conversations. By doing this, you can put together a realistic estimate of the questions your real users are likely to ask.
Outlining the conversational flow
Conversations tend to follow patterns we can use to identify common intents our assistant should anticipate. For example, many conversations follow this structure:
- Greeting
- Assistant states what it is capable of (this is a good practice for a better user experience)
- User states what they are looking for
- Assistant asks for more details OR
- Answers the query if enough information has been provided
- User says thank you
- Assistant says "you're welcome" and goodbye
This sequence may seem simple, but conversation design is actually a challenging task. Real-life conversations have more back and forth interactions, and it's difficult to anticipate everything users might ask. When you try to invent a large number of hypothetical conversations to train your model, you risk introducing bias into your data. Because of this, you should only rely on hypothetical conversations in the early stages of development and train your assistant on real conversations as soon as possible.
Generating NLU Training Data for the Medicare Locator
InEpisode 1, we installed Rasa and created a new starter project using the rasa init command. We'll build on previous steps in this and later episodes, so be sure to head back to Episode 1 to get up to speed if you're just joining.
The moodbot starter project contains a Data directory, where you'll find the training data files for NLU and dialogue management models. The Data directory contains two files:
- nlu.md - the file containing NLU model training examples. This includes intents, which are user goals, and example utterances that represent those intents. The NLU training data also labels the entities, or important keywords, the assistant should extract from the example utterance.
- stories.md - the file containing story data. Stories are example end-to-end conversations.
For now, we'll concentrate on the nlu.md file:
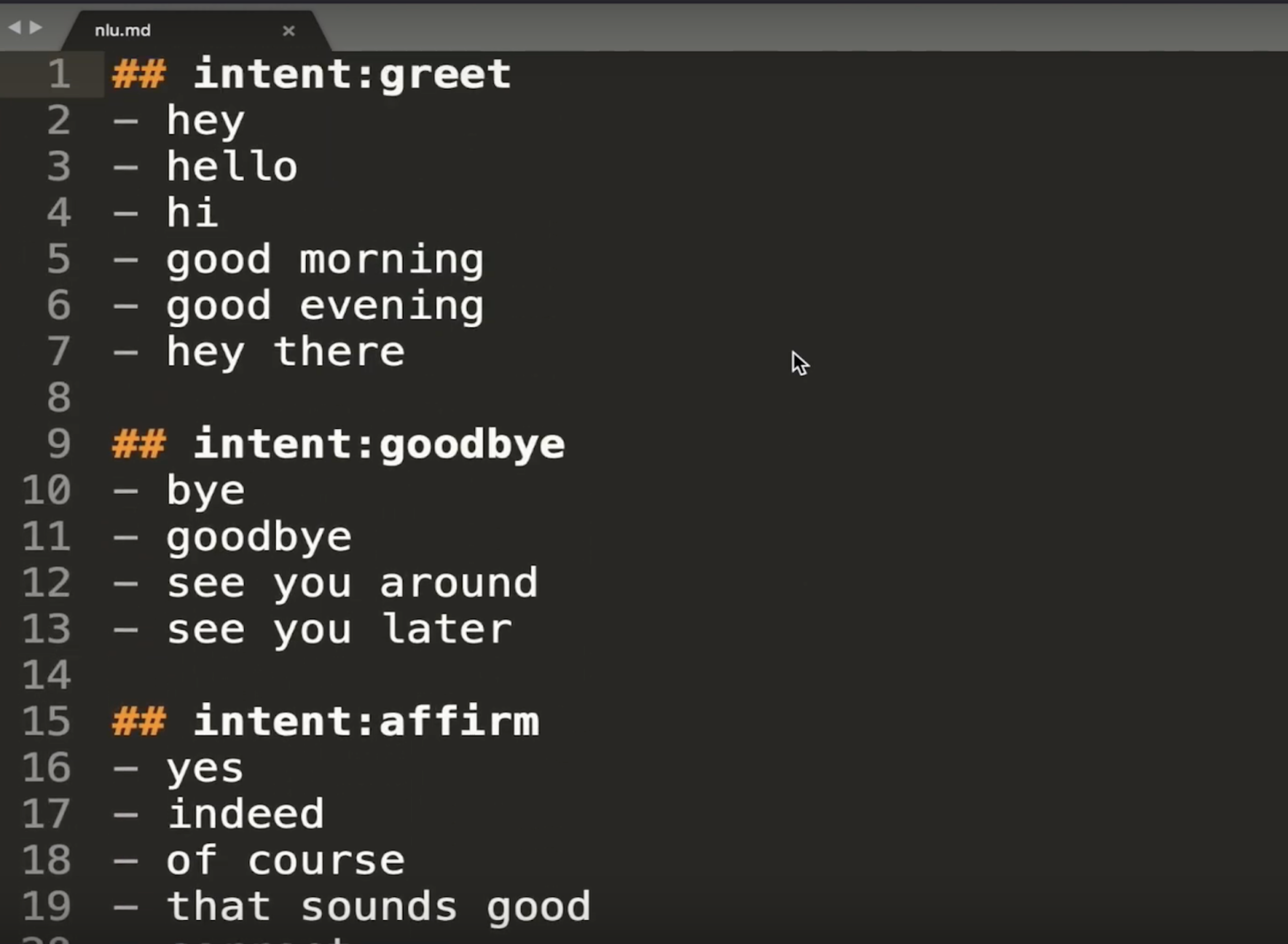
Intents are defined using a double hashtag. Each intent is followed by multiple examples of how a user might express that intent.
Entities are labeled with square brackets and tagged with their type in parentheses.
For example, in the nlu.md file for the Medicare Locator, we've created an intent called search_provider, which represents a user's request to locate a healthcare facility. In each example utterance, we've labeled entities for location and facility type.
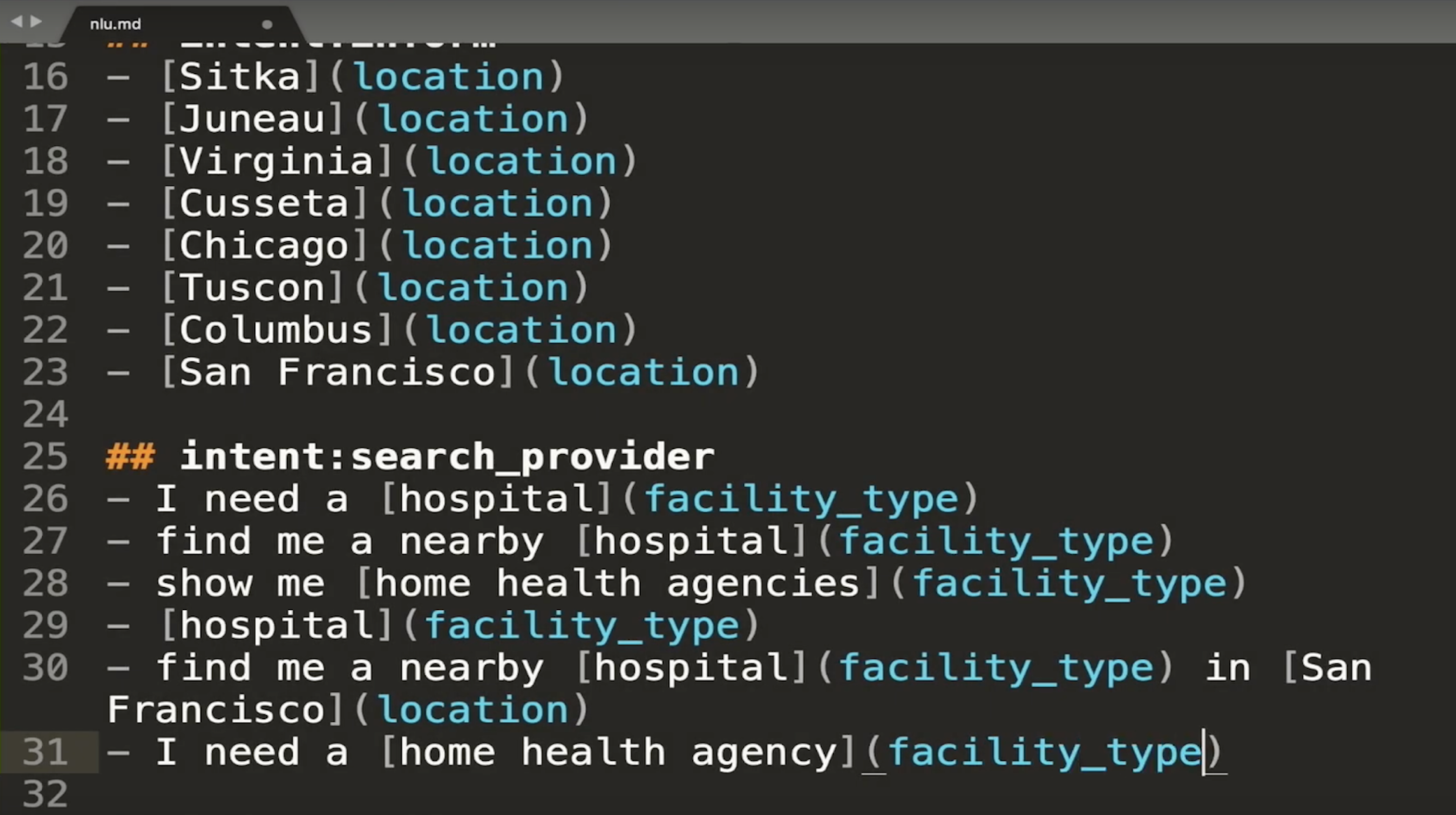
Each intent your assistant is capable of understanding will need to be defined in the nlu.md file. There are a few best practices to keep in mind:
- You don't need to write every possible utterance to train an intent, but you should provide 10-15 examples.
- Make sure you provide high-quality data to train your model. Examples should be relevant to the intents, and be sure that there's plenty of diversity in the vocabulary you use in your examples.
Next Steps
Take some time to practice what you've learned by defining a few new intents in your nlu.md file. Then, continue on to Episode 3, where we'll discuss the NLU training pipeline.
Additional Resources
- Creating the NLU training data - Rasa Masterclass Ep.#2 (YouTube)
- NLU Training Data Format (Rasa docs)Rasa X - NLU Training (Rasa docs)