



The Rasa Masterclass is a weekly video series that takes viewers through the process of building an AI assistant, all the way from idea to production. Hosted by Head of Developer Relations Justina Petraityte, each episode focuses on a key concept of building sophisticated AI assistants with Rasa and applies those learnings to a hands-on project. At the end of the series, viewers will have built a fully-functioning AI assistant that can locate medical facilities in US cities.
To supplement the video content, we'll be releasing blog posts to summarize each episode. You can follow along with these posts as you watch to reinforce your understanding, or you can use them as a quick reference. We'll also include links to additional resources you can use to help you along your journey.
Introduction
Episode 3 of the Rasa Masterclass is the first of a 2-part module on training NLU models. In this portion, we'll focus on:
- Choosing a training pipeline configuration
- Training the model
- Testing the model
Key Concepts
Let's begin with a few important definitions:
NLU model - An NLU model is used to extract meaning from text input. In our previous episode, we discussed how to create training data, which contains labeled examples of intents and entities. Training an NLU model on this data allows the model to make predictions about the intents and entities in new user messages, even when the message doesn't match any of the examples the model has seen before.
Training pipeline - NLU models are created through a training pipeline, also referred to as a processing pipeline. A training pipeline is a sequence of processing steps which allow the model to learn the training data's underlying patterns.
In our next episode, we'll dive deeper into the inner workings of the individual pipeline components, but for now, we'll focus on the two pre-configured pipelines included with Rasa out-of-the-box. These pre-configured pipelines are a great fit for the majority of general use cases. If you're looking for information on configuring a custom training pipeline, we'll cover the topic in Episode 4.
Word embeddings - Word embeddings convert words to vectors, or dense numeric representations based on multiple dimensions. Similar words are represented by similar vectors, which allows the technique to capture their meaning. Word embeddings are used by the training pipeline components to make text data understandable to the machine learning model.
Choosing a Pipeline Configuration
Rasa comes with two default, pre-configured pipelines. Both pipelines are capable of performing intent classification and entity extraction. In this section, we'll compare and contrast the two options to help you choose the right pipeline configuration for your assistant.
- Pretrained_embeddings_spacy - Uses the spaCy library to load pre-trained language models, which are used to represent each word in the user's input as word embeddings.
- Advantages
- Boosts the accuracy of your models, even if you have very little training data.
- Training doesn't start from scratch, which makes it blazing fast. This encourages short iteration times, so you can rapidly improve your assistant.
- Considerations
- Complete and accurate word embeddings are not available for all languages. They're trained on publicly available datasets, which are mostly in English.
- Word embeddings don't cover domain-specific words, like product names or acronyms, because they're often trained on generic data, like Wikipedia articles.
- Advantages
- Supervised_embeddings - Unlike pre-trained embeddings, the supervised_embeddings pipeline trains the model from scratch using the data provided in the NLU training data file.
- Advantages
- Can adapt to domain-specific words and messages, because the model is trained on your training data.
- Language-agnostic. Allows you to build assistants in any language.
- Supports messages with multiple intents.
- Considerations
- Compared to pre-trained embeddings, you'll need more training examples for your model to start understanding unfamiliar user inputs. The recommended number of examples is 1000 or more.
- Advantages
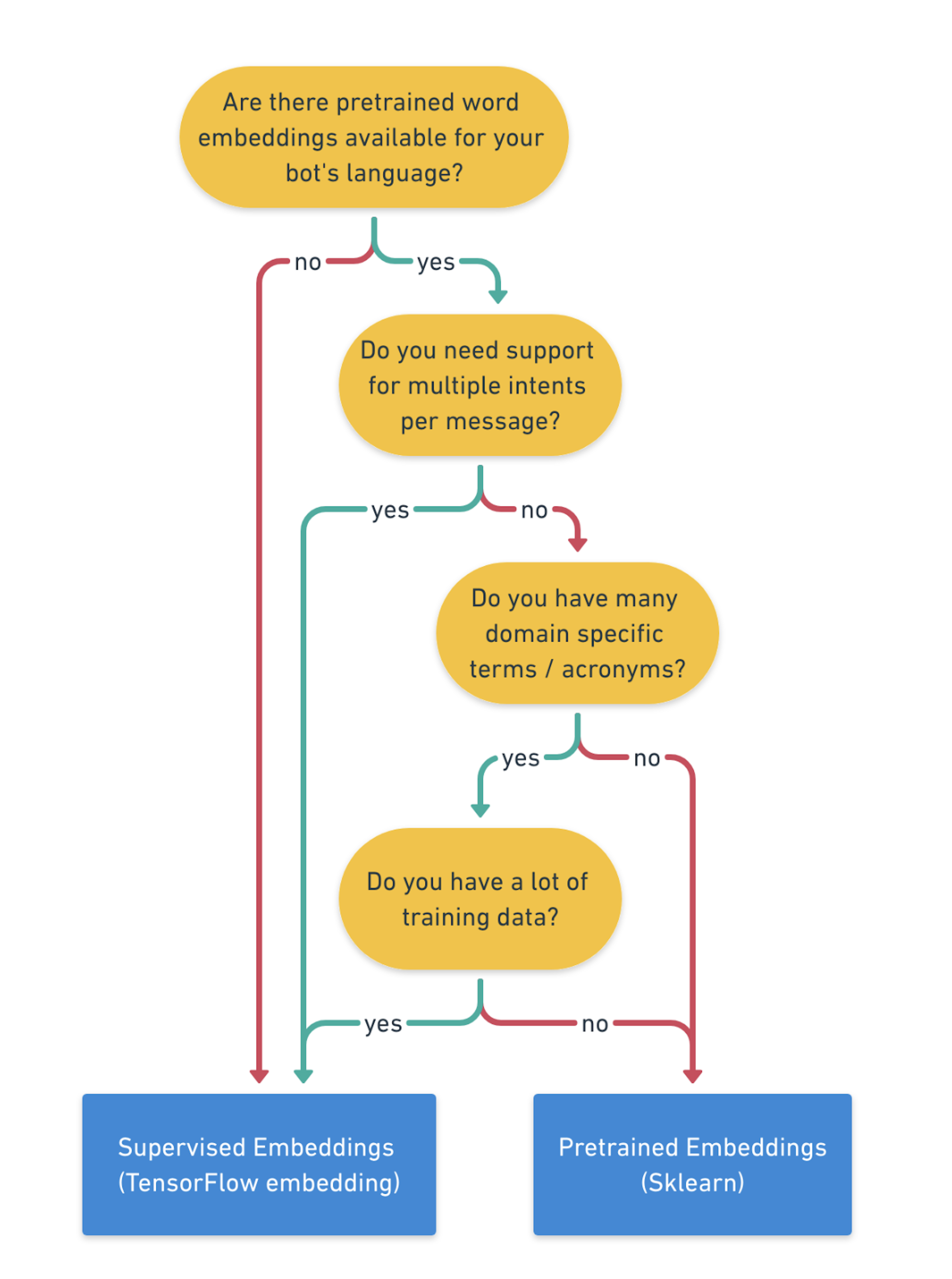
Generally speaking, the pretrained_embeddings_spacy pipeline is the best choice when you don't have a lot of training data and your assistant will be fairly simple. The supervised_embeddings pipeline is the best choice when your assistant will be more complex, especially if you need to support non-English languages. This decision tree illustrates the factors you will want to consider when deciding which pre-configured pipeline is right for your project:
Training the Model
After you've created your training data (see Episode 2 for a refresher on this topic), you are ready to configure your pipeline, which will train a model on that data. Your assistant's processing pipeline is defined in the config.yml file, which is automatically generated when you create a starter project using the rasa init command.
This example shows how to configure the supervised_embeddings pipeline, by defining the language indicator and the pipeline name:
language: "en"
pipeline: "supervised_embeddings"
To train an NLU model using the supervised_embeddings pipeline, define it in your config.yml file and then run the Rasa CLI command rasa train nlu. This command will train the model on your training data and save it in a directory called models.
To change the pipeline configuration to pretrained_embeddings_spacy, edit the language parameter in config.yml to match the appropriate spaCy language model and update the pipeline name. You can now retrain the model using the rasa train NLU command.
Testing the Model
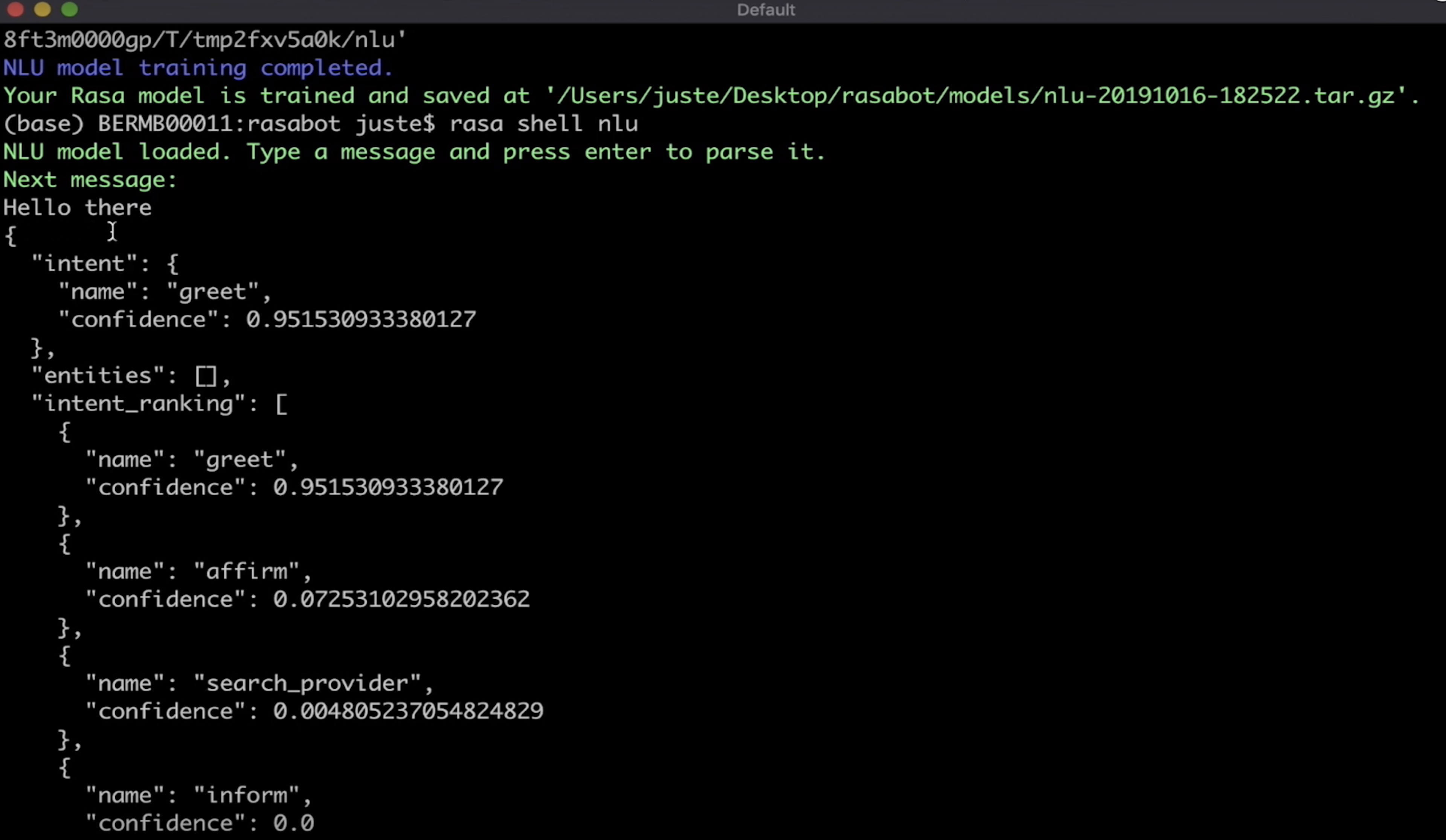
Test the newly trained model by running the Rasa CLI command, rasa shell nlu. This loads the most recently trained NLU model and allows you to test its performance by conversing with the assistant on the command line.
While in test mode, type a message in your terminal, for example, 'Hello there.' Rasa CLI outputs a JSON object containing several useful pieces of data:
-
The intent the model thinks is the most likely match for the message.
For example:
{"name: greet", "confidence: 0.95347273804"}. This means the model is 95% certain "Hello there" is a greeting. -
A list of extracted entities, if there are any.
-
A list of intent_rankings. These results show the intent classification for all of the other intents defined in the training data. The intents are ranked according to the model's prediction of an intent match.
Next Steps
Pre-configured pipelines are a great way to get started quickly, but as your project grows in complexity, you will probably want to customize your model. Similarly, as your knowledge and comfort level increases, it's important to understand how the components of the processing pipeline work under the hood. This deeper understanding will help you diagnose why your models behave a certain way and optimize the performance of your training data.
Continue on to our next episode, where we'll explore these topics in part 2 of our module on NLU model training: Training the NLU models: understanding pipeline components (Rasa Masterclass Ep.#4).
Additional Resources
- Training the NLU model: pre-configured pipelines - Rasa Masterclass ep.#3 (YouTube)
- Choosing a Pipeline (Rasa docs)
- Supervised Word Vectors from Scratch in Rasa NLU (Rasa blog)
- Spacy 101 (Spacy docs)