


December 10th, 2019
The Rasa Masterclass Handbook: Episode 4
Rasa

The Rasa Masterclass is a weekly video series that takes viewers through the process of building an AI assistant, all the way from idea to production. Hosted by Head of Developer Relations Justina Petraityte, each episode focuses on a key concept of building sophisticated AI assistants with Rasa and applies those learnings to a hands-on project. At the end of the series, viewers will have built a fully-functioning AI assistant that can locate medical facilities in US cities.
To supplement the video content, we'll be releasing blog posts to summarize each episode. You can follow along with these posts as you watch to reinforce your understanding, or you can use them as a quick reference. We'll also include links to additional resources you can use to help you along your journey
Introduction
Episode 4 of the Rasa Masterclass is the second of a two-part module on training NLU models. As we saw in Episode 3, Rasa allows you to define the pipeline used to generate NLU models, but you can also configure the individual components of the pipeline, to completely customize your NLU model. In Episode 4, we'll examine what each component does and what's happening under the hood when a model is trained.
This episode builds upon the material we covered previously, so if you're just joining, head back and watch Episode 3 before proceeding.
First, a quick recap of the most important concepts covered in Episode 3:
- NLU models accept user messages as input and output predictions about the intents and entities contained in those messages.
- A training pipeline trains a new NLU model using a sequence of processing steps that allow the model to learn the training data's underlying patterns.
- Rasa comes with two pre-configured pipelines:
- Pretrained_embeddings_spacy - Uses the spaCy pre-trained language model. Pre-trained models allow you to supply fewer training examples and get started quickly; however, they're trained primarily on general-purpose English data sets, so support for domain-specific terms and non-English languages is limited.
- Supervised_embeddings - Trains the model from scratch using the data provided in the NLU training data file. Supervised training supports any language that can be tokenized and can be trained to understand domain-specific terms, but a greater number of training examples is required.
- In a Rasa project, the training pipeline is defined in the config.yml file:
language: "en"pipeline: "pretrained_embeddings_spacy"Training Pipeline Overview
Before going deeper into individual pipeline components, it's helpful to step back and take a birds-eye view of the process.
As mentioned earlier, a training pipeline consists of a sequence of steps that train a model using NLU data. Each pipeline step executes one after the other, and the order of the steps matters. Some steps produce output that a later step needs to accept as input. Imagine an assembly line in a factory: the worker at the end of the line can't attach the final piece until other workers have attached their pieces. So the pipeline doesn't just define which components should be present, but also the order in which they should be arranged.
No matter which pipeline you choose, it will follow the same basic sequence. We'll outline the process here and then describe each step in greater detail in the Components section.
- Load pre-trained language model (optional). Only needed if you're using a pre-trained model like spaCy.
- Tokenize the data. Splits the training data text into individual words, or tokens.
- Named Entity Recognition. Teaches the model to recognize which words in a message are entities and what type of entity they are.
- Featurization. Converts tokens to vectors, or dense numeric representations of words. This step can be performed before or after Named Entity Recognition, but must come after tokenization and before Intent Classification.
- Intent Classification. Trains the model to make a prediction about the most likely meaning behind a user's message
After a model has been trained using this series of components, it will be able to accept raw text data and make a prediction about which intents and entities the text contains.
Training Pipeline Components
So far, we've talked about two processing pipelines: supervised_embeddings and pretrained_embeddings_spacy. Both pipelines consist of components that are responsible for different tasks. In the following sections, we'll examine each component in greater detail.

SpacyNLP
The pretrained_embeddings_spacy pipeline uses the SpacyNLP component to load the Spacy language model so it can be used by subsequent processing steps. You only need to include this component in pipelines that use spaCy for pre-trained embeddings, and it needs to be placed at the very beginning of the pipeline.
Tokenizer
Tokenizers take a stream of text and split it into smaller chunks, or tokens; usually individual words. The tokenizer should be one of the first steps in the processing pipeline because it prepares text data to be used in subsequent steps. All training pipelines need to include a tokenizer, and there are several you can choose from:
WhitespaceTokenizer - The way a whitespace tokenizer works is very simple: it looks for whitespace in a stream of text and uses it as a delimiter to separate each token, or word. A whitespace tokenizer is the default tokenizer used by the supervised_embeddings pipeline, and it's a good choice if you don't plan on using pre-trained embeddings.
Jieba - Whitespace works well for English and many other languages, but you may need to support languages that require more specific tokenization rules. In that case, you'll want to reach for a language-specific tokenizer, like Jieba for the Chinese language.
SpacyTokenizer - Pipelines that use spaCy come bundled with the SpacyTokenizer, which segments text into words and punctuation according to rules specific to each language. This is a good option if you're using pre-trained embeddings.

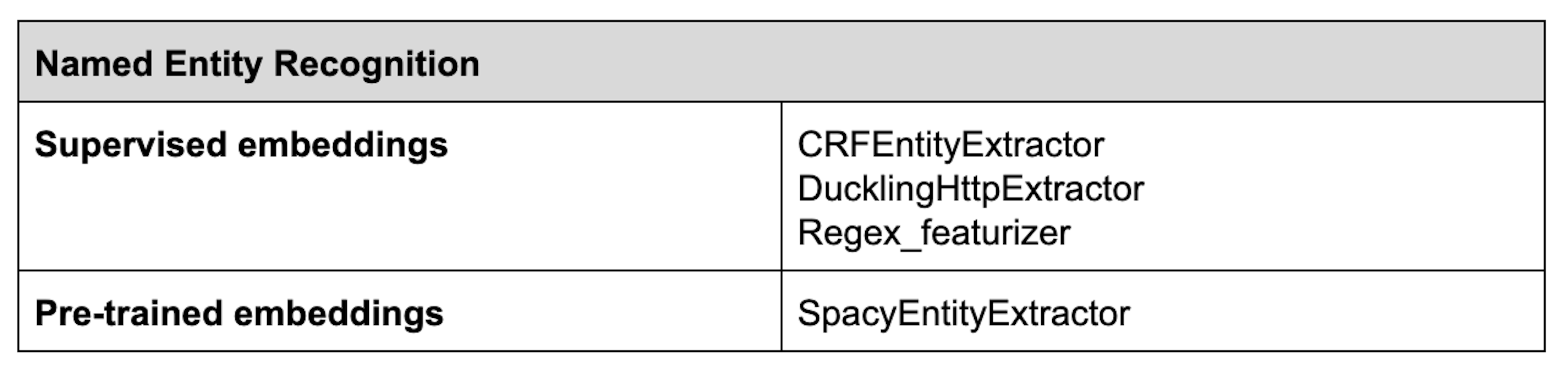
Named Entity Recognition (NER)
NLU models use named entity recognition components to extract entities from user messages. For example, if a user says "What's the best coffee shop in San Francisco?" the model should extract the entities 'coffee shop' and 'San Francisco', and identify them as a type of business and a location. There are a few named entity recognition components you can choose from when assembling your training pipeline:
CRFEntityExtractor - CRFEntityExtractor works by building a model called a Conditional Random Field. This method identifies the entities in a sentence by observing the text features of a target word as well as the words surrounding it in the sentence. Those features can include the prefix or suffix of the target word, capitalization, whether the word contains numeric digits, etc. You can also use part of speech tagging with CRFEntityExtractor, but it requires installing spaCy. Part of speech tagging looks at a word's definition and context to determine its grammatical part of speech, e.g. noun, adverb, adjective, etc.
Unlike tokenizers, whose output is fed into subsequent pipeline components, the output produced by CRFEntityExtractor and other named entity recognition components is actually expressed in the final output of the NLU model. It outputs which words in a sentence are entities, what kind of entities they are, and how confident the model was in making the prediction.
SpacyEntityExtractor - If you're using pre-trained word embeddings, you have the option to use SpacyEntityExtractor for named entity recognition. Even when trained on small data sets, SpacyEntityExtractor can leverage part of speech tagging and other features to locate the entities in your training examples.
DucklingHttpExtractor - Some types of entities follow certain patterns, like dates. You can use specialized NER components to extract these types of structured entities. DucklingHttpExtractor recognizes dates, numbers, distances and data types.
Regex_featurizer - The regex_featurizer component can be added before CRFEntityExtractor to assist with entity extraction when you're using regular expressions and/or lookup tables. Regular expressions match certain hardcoded patterns, like a 10-digit phone number or an email address. Lookup tables provide a predefined range of values for an entity. They're useful if your entity type has a finite number of possible values. For example, there are 195 possible values for the entity type 'country,' which could all be listed in a lookup table.
Intent Classification
There are two types of components that work together to classify intents: featurizers and intent classification models.
Featurizers take tokens, or individual words, and encode them as vectors, which are numeric representations of words based on multiple attributes. The intent classification model takes the output of the featurizer and uses it to make a prediction about which intent matches the user's message. The output of the intent classification model is expressed in the final output of the NLU model as a list of intent predictions, from the top prediction down to a ranked list of the intents that didn't "win."
{ "intent": {"name": "greet", "confidence": 0.8343}, "intent_ranking": [ { "confidence": 0.385910906220309, "name": "goodbye" }, { "confidence": 0.28161531595656784, "name": "restaurant_search" } ]}Featurizer
CountVectorsFeaturizer - This featurizer creates a bag-of-words representation of a user's message using sklearn's CountVectorizer. The bag-of-words model disregards the order of words in a body of text and instead focuses on the number of times words appear in the text. So the CountVectorsFeaturizer counts how often certain words from your training data appear in a message and provides that as input for the intent classifier.
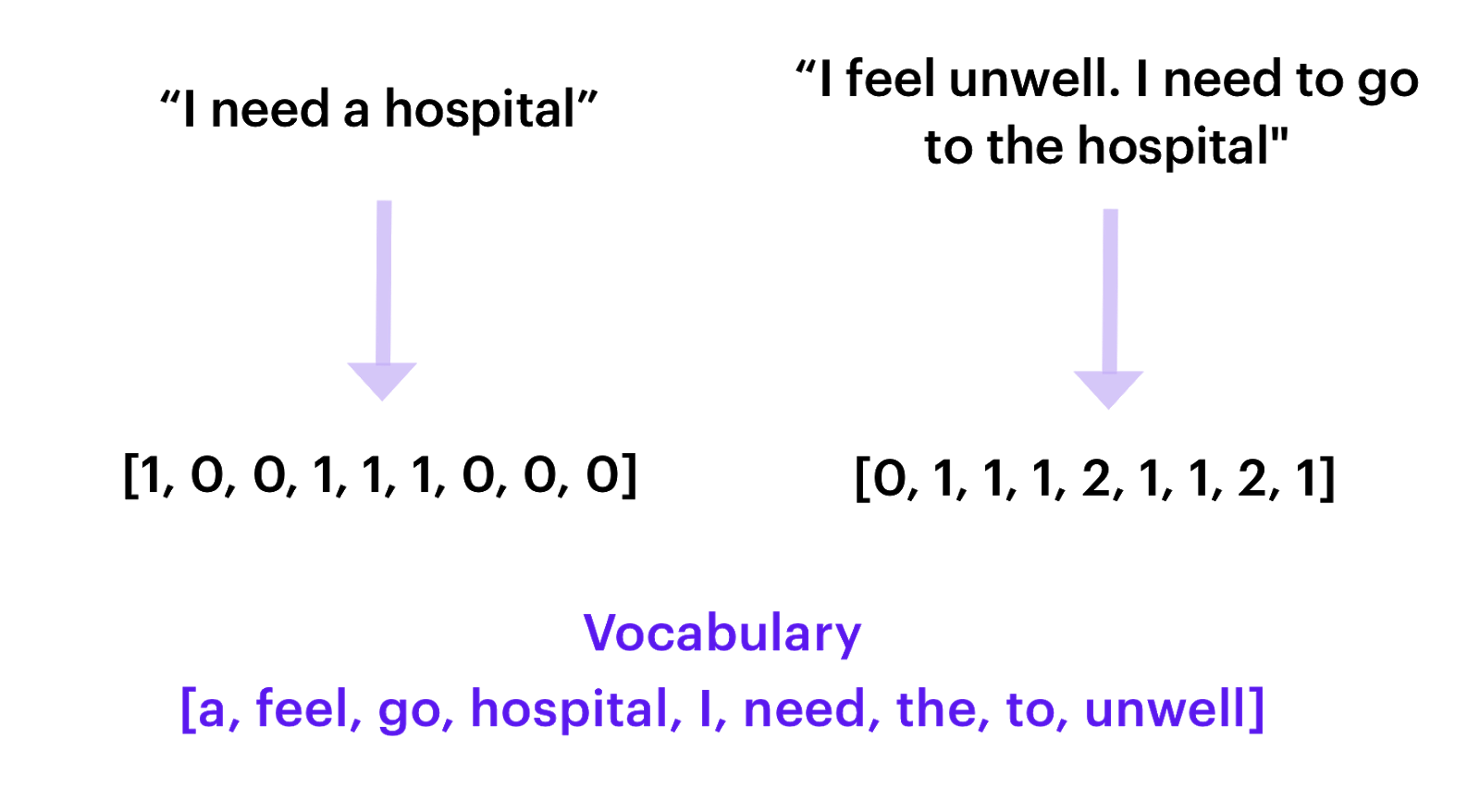
CountVectorsFeaturizer can be configured to use either word or character n-grams, which is defined using the analyzer config parameter. An n-gram is a sequence of n items in text data, where n represents the linguistic units used to split the data, e.g. by characters, syllables, or words.
By default, the analyzer is set to word n-grams, so word token counts are used as features. If you want to use character n-grams, set the analyzer to char or char_wb. You can also use character n-gram counts by changing the analyzer property of the intent_featurizer_count_vectors component to char. This makes the intent classification more resilient to typos, but also increases the training time.
- name: "CountVectorsFeaturizer" analyzer:"char_web" min_ngram: 1 max_ngram: 4SpacyFeaturizer - If you're using pre-trained embeddings, SpacyFeaturizer is the featurizer component you'll likely want to use. It returns spaCy word vectors for each token, which is then passed to the SklearnIntent Classifier for intent classification.
Intent Classifier
EmbeddingIntentClassifier - If you're using the CountVectorsFeaturizer in your pipeline, we recommend using the EmbeddingIntentClassifier component for intent classification. The features extracted by the CountVectorsFeaturizer are transferred to the EmbeddingIntentClassifier to produce intent predictions.
The EmbeddingIntentClassifier works by feeding user message inputs and intent labels from training data into two separate neural networks which each terminate in an embedding layer. The cosine similarities between the embedded message inputs and the embedded intent labels are calculated, and supervised embeddings are trained by maximizing the similarities with the target label and minimizing similarities with incorrect ones. The results are intent predictions that are expressed in the final output of the NLU model.

SklearnIntentClassifier - When using pre-trained word embeddings, you should use the SklearnIntentClassifier component for intent classification. This component uses the features extracted by the SpacyFeaturizer as well as pre-trained word embeddings to train a model called a Support Vector Machine (SVM). The SVM model predicts the intent of user input based on observed text features. The output is an object showing the top ranked intent and an array listing the rankings of other possible intents.

FAQ
Now that we've discussed the components that make up the NLU training pipeline, let's look at some of the most common questions developers have about training NLU models.
Q. Does the order of the components in the pipeline matter?
A. The short answer: yes! Some components need the output from a previous component in order to do their jobs. As a rule of thumb, your tokenizer should be at the beginning of the pipeline, and the featurizer should come before the intent classifier.
Q.Should I worry about class imbalance in my NLU training data?
A. Class imbalance is when some intents in the training data file have many more examples than others. And yes-this can affect the performance of your model. To mitigate this problem, Rasa's supervised_embeddings pipeline uses a balanced batching strategy. This algorithm distributes classes across batches to balance the data set. To prevent oversampling rare classes and undersampling frequent ones, it keeps the number of examples per batch roughly proportional to the relative number of examples in the overall data set.
Q.Does the punctuation in my training examples matter?
A. Punctuation is not extracted as tokens, so it's not expressed in the features used to train the models. That's why punctuation in your training examples should not affect the intent classification and entity extraction results.
Q.Are intent classification and entity extraction case sensitive?
A. It depends on the task. Named Entity Recognition does observe whether tokens are upper- or lowercase. Case sensitivity also affects the results of entity extraction models.
CountVectorsFeaturizer, however, converts characters to lowercase by default. For that reason, upper- or lowercase words don't really affect the performance of the intent classification model, but you can customize the model parameters if needed.
Q.Some of the intents in my training data are pretty similar. What should I do?
A. When the intents in your training data start to seem very similar, it's a good idea to evaluate whether the intents can be combined into one. For example, imagine a scenario where a user provides their name or a date. Intuitively you might create a provide_name intent for the message "It is Sara," and a provide_date intent for the message "It is on Monday." However, from an NLU perspective, these messages are very similar except for their entities. For this reason it would be better to create an intent called inform which unifies provide_name and provide_date. Later on, in your dialogue management training data, you can define different story paths depending on which entity Rasa NLU extracted.
Q. What if I want to extract entities from one-word inputs?
A. Extracting entities from one-word user inputs is still quite challenging. The best technique is to create a specific intent, for example inform, which would contain examples of how users provide information, even if those inputs consist of one word. You should label the entities in those examples as you would with any other example, and use them to train intent classification and entity extraction models.
Q. Can I specify more than one intent classification model in my pipeline?
A. Technically yes, but there is no real benefit. The predictions of the last specified intent classification model will always be what's expressed in the output.
Q. How do I deal with typos in user inputs?
A. Typos in user messages are unavoidable, but there are a few things you can do to address the problem. One solution is to implement a custom spell checker and add it to your pipeline configuration. This is a nice way to fix typos in extracted entities. Another thing you can do is to add some examples with typos to your training data for your models to pick up.
Conclusion
Choosing the components in a custom pipeline can require experimentation to achieve the best results. But after applying the knowledge gained from this episode, you'll be well on your way to confidently configuring your NLU models.
After you finish this episode of the Rasa Masterclass, keep up the momentum. Watch the next installment in the series: Episode 5, Intro to dialogue management. Then, join us in the community forum to discuss!
Additional Resources
- Training the NLU models: understanding pipeline components - Rasa Masterclass Ep.#4 (YouTube)
- Entity Extraction (Rasa docs)
- NLU Components (Rasa docs)
- Rasa NLU In Depth: Part 1 - Intent Classification (Rasa Blog)
- Rasa NLU in Depth: Part 2 - Entity Recognition (Rasa Blog)