



The Rasa Masterclass is a weekly video series that takes viewers through the process of building an AI assistant, all the way from idea to production. Hosted by Head of Developer Relations Justina Petraityte, each episode focuses on a key concept of building sophisticated AI assistants with Rasa and applies those learnings to a hands-on project. At the end of the series, viewers will have built a fully-functioning AI assistant that can locate medical facilities in US cities.
To supplement the video content, we'll be releasing these handbooks to summarize each episode. You can follow along as you watch to reinforce your understanding, or you can use them as a quick reference. We'll also include links to additional resources you can use to help you along your journey.
Introduction
In Episode 7 of the Rasa Masterclass, we cover dialogue policies. In our last few episodes, we've been discussing dialogue management-the process that determines what an assistant does next in response to user input. Policies are components that train the dialogue model, and they play a very important role in determining its behavior. Some policies are quite simple, like those that mirror the conversations they've been trained on, and some are quite complex, like those that rely on sophisticated machine learning to predict the next action based on the context of the conversation.

In this episode, we'll cover the policies that are available in Rasa, how developers can configure them, and how to decide which policies to use. Because we'll be building on concepts covered in previous episodes, be sure to watch Episode 5 and Episode 6 before proceeding.
Policy Configuration in Rasa
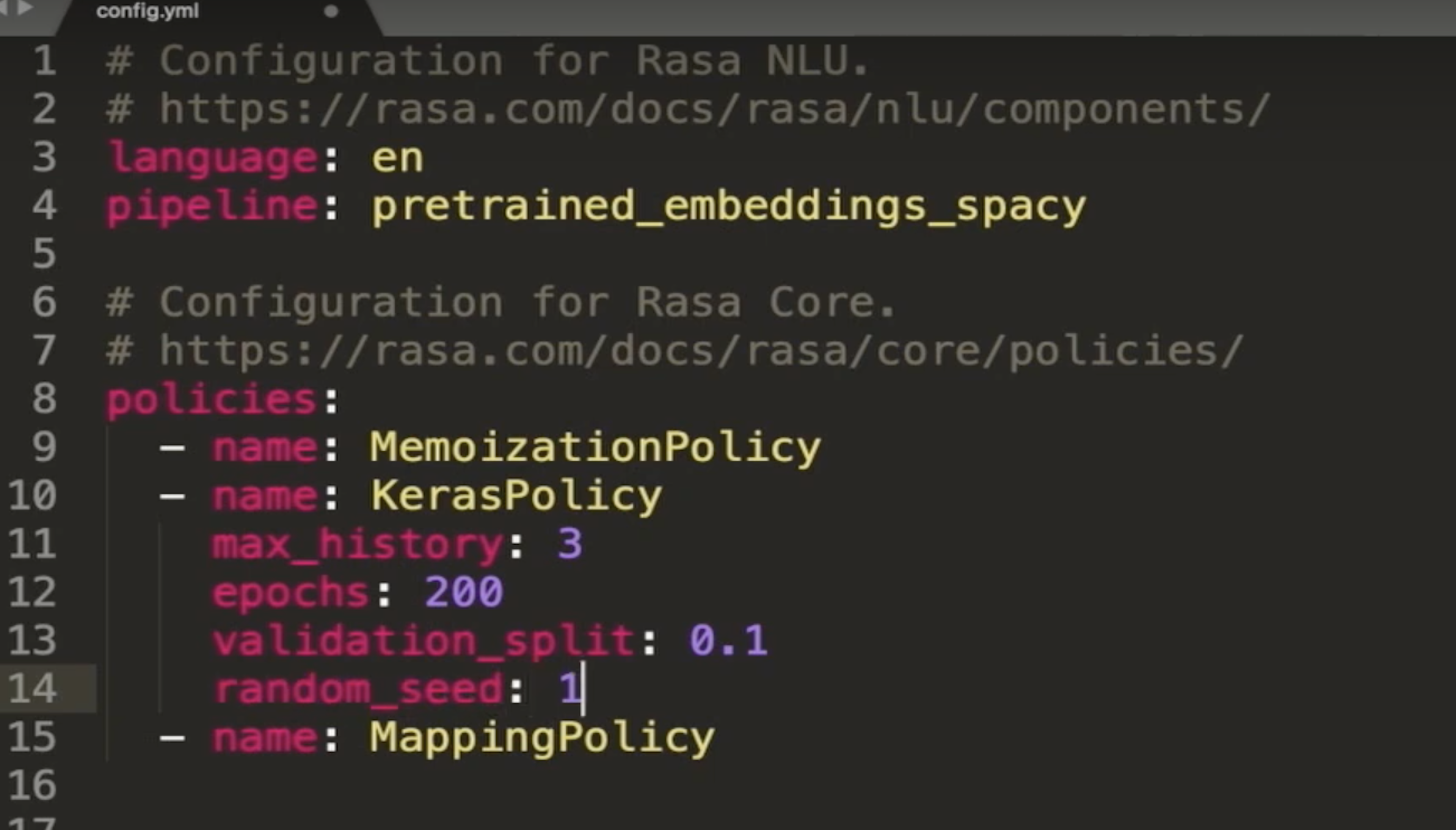
Just like the NLU training pipeline we configured in Episode 4, dialogue policies are also configured in the config.yml file, which you'll find in your main project directory.
Let's take a look at the default configuration generated by rasa init:

The policy configuration is defined by a list of policy names, along with optional parameters that can be configured by developers. Unlike the NLU training pipeline, which runs components sequentially, dialogue policies run in parallel. At each conversational turn, each policy in the configuration makes its own prediction about the next best action. The policy that predicts the next action with the highest confidence level determines the assistant's next action.

In cases where two policies predict with equal confidence, a priority system kicks in to decide which policy will "win." Rasa automatically weights policies according to default priority levels, which are tuned to make sure the assistant chooses the most appropriate action when there's a tie. Higher numbers are given higher priority, and machine learning policies are given a priority of 1:
-
FormPolicy
-
FallbackPolicy and TwoStageFallbackPolicy
-
MemoizationPolicy and AugmentedMemoizationPolicy
-
MappingPolicy
-
EmbeddingPolicy, KerasPolicy, and SklearnPolicy
Generally speaking, you should only have one policy per priority level to avoid conflicts, and some policies, like Fallback and TwoStageFallback, explicitly cannot be used together. We'll discuss configuration in greater detail when we cover each policy in depth. For now, keep in mind that multiple policies can be used together, and the highest confidence, highest priority policy predicts the assistant's next action.
Hyperparameters
While individual policies have their own unique parameters that can be configured to adjust the model's behavior, there are two important parameters that are common to all Rasa core dialogue policies: max-history and data augmentation.
Max-history
When a policy makes a prediction about the next action to take, it doesn't just look at the last thing the user said. It also considers what's happened in previous conversational turns. The max-history parameter controls how many previous conversational turns the policy should look at when making a prediction. This can be especially useful if you want to train your assistant to respond to certain patterns in user messages, like repeated off topic requests.
Let's use our medicare locator assistant, which helps users locate nearby medical facilities, as an example. If a user asked the assistant several times in a row where to find the nearest Italian restaurant, we'd probably want the assistant to respond with a help message telling the user what it can help with. Assuming we'd defined an out_of_scope intent to catch off-topic requests, the story might look like this:
* out_of_scope
- utter_default
* out_of_scope
- utter_default
* out_of_scope
- utter_help_message
In order for the assistant to pick up this pattern, we'd need to set the max_history to at least 3.
So a higher max_history is always better, right? Not so fast. A higher max_history creates a larger model, which can cause performance issues. If you need your assistant to remember certain details from farther back in the conversation, it's better to save those details as slots instead of setting max_history to a very large number.
Data augmentation
By default, Rasa core combines randomly-selected stories in your training data file, a process known as data augmentation. Data augmentation is used to teach the model to ignore conversation history when it's not relevant. For example, with short stories like these, the next action should be the same, no matter what happened before in the conversation:


You can control this behavior using the --augmentation flag in the policy configuration. By default, augmentation is set to a factor of 20, which creates 200 augmented stories. A higher factor increases the amount of data the model has to process and results in higher training times. Setting --augmentation 0 disables the behavior, which you might want to do if you have a lot of training examples.
Dialogue Policies
Now, we'll discuss the available Rasa training policies, one by one. The policies are:
- Memoization Policy
- Mapping Policy
- Keras Policy
- Embedding Policy (TEDP)
- FormPolicy
- FallbackPolicy
For each policy, we'll discuss how the policy makes predictions and influences the behavior of Rasa core, as well as the parameters available for developers to configure.
Memoization Policy
The Memoization Policy is one of the simpler dialogue policies we'll discuss. It snips the part of the conversation defined by the max_history (so if max_history: 3, 3 turns back), and looks for a matching story fragment in the training data set. If it finds a match, it predicts the same next action seen in the training data.

An important detail about the Memoization Policy is that it predicts with 100% certainty: if a match is found in the training data, it predicts the next action with a confidence level of 1, otherwise it predicts None, with a confidence level of 0.
The Memoization policy is very useful for making sure your assistant follows the stories you've provided in your training data. It enforces the patterns and conversational paths you want your assistant to follow, much like a set of rules. However, when a match isn't found in the training data, the Memoization policy can't provide a next action. That's why the Memoization Policy isn't meant to be used on its own-it's used with other policies that fill in the gaps when an exact match isn't available.
Configuration
- Max_history - Determines the length of story fragments an assistant should consider when making the next prediction. Default configuration is 5
- Priority - While you can reset the policy's priority, we recommend leaving this as the default.
Mapping Policy
The Mapping Policy maps an intent to a specific action. This is useful when you know that an intent should always be followed by a certain response, regardless of what has happened previously in the conversation. For example, if the user asks if they're speaking to a bot in the middle of the conversation, the assistant should always respond with the same message, without breaking the flow of conversation.
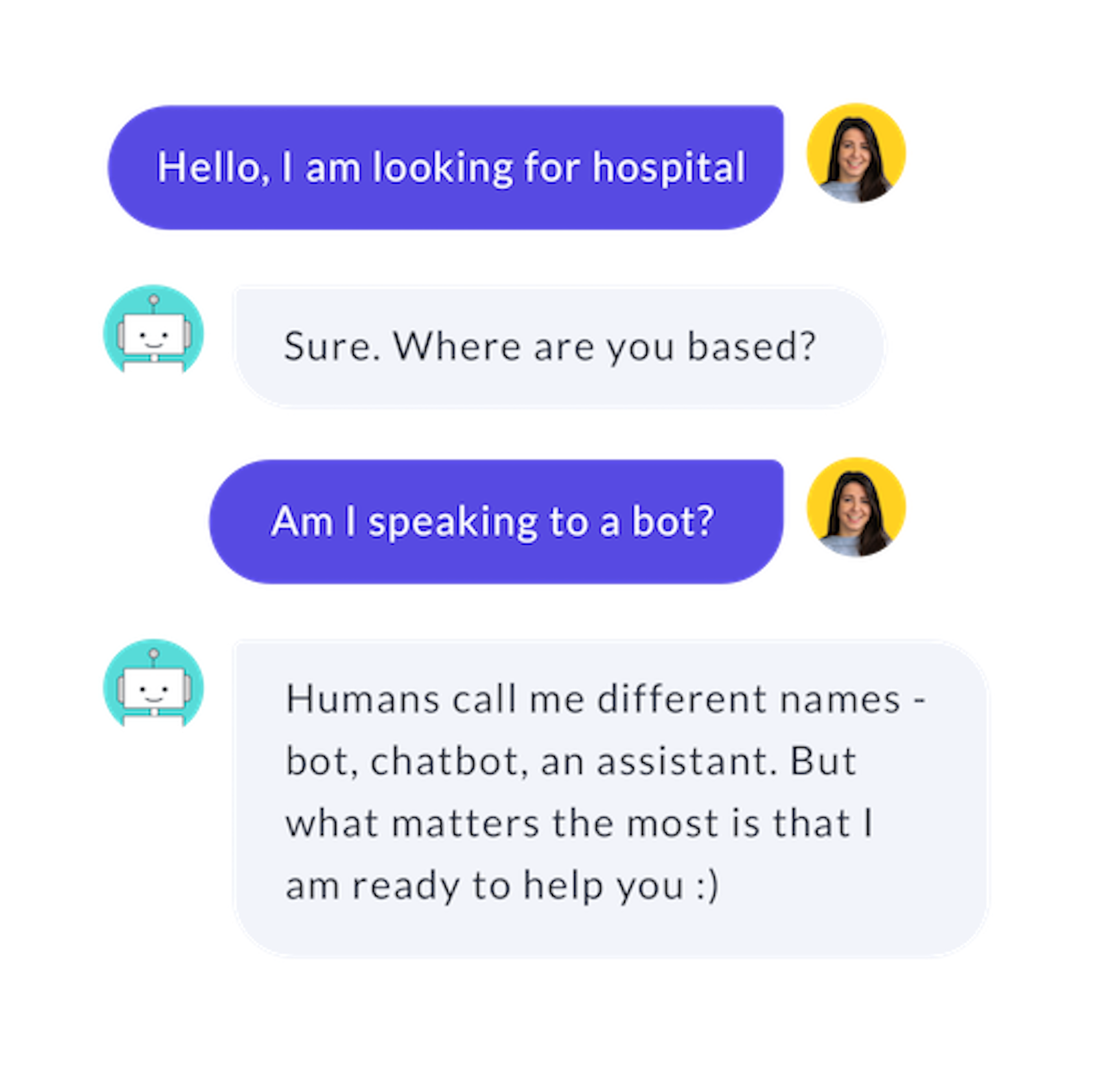
Because the Mapping Policy is so specialized, it will always need to be used in combination with other policies, to generate action predictions outside of those that have been explicitly mapped.
Configuration
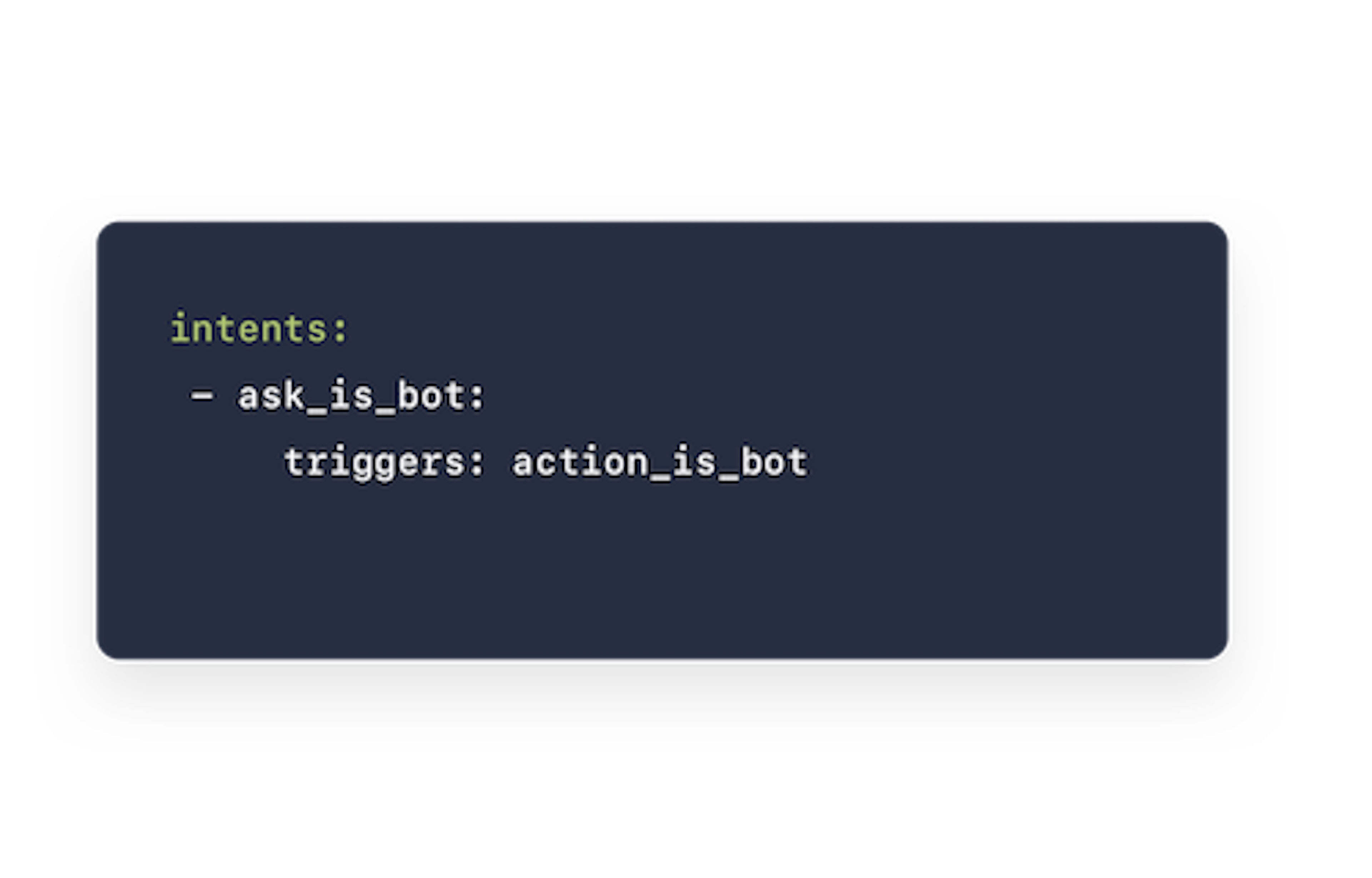
To enable the mapping policy, include MappingPolicy in your config.yml policies and then map intents to actions in the domain.yml file, using the triggers property. An intent can be mapped only to a single action.
Here, we're mapping the ask_is_bot intent to a custom action that prints a response message.
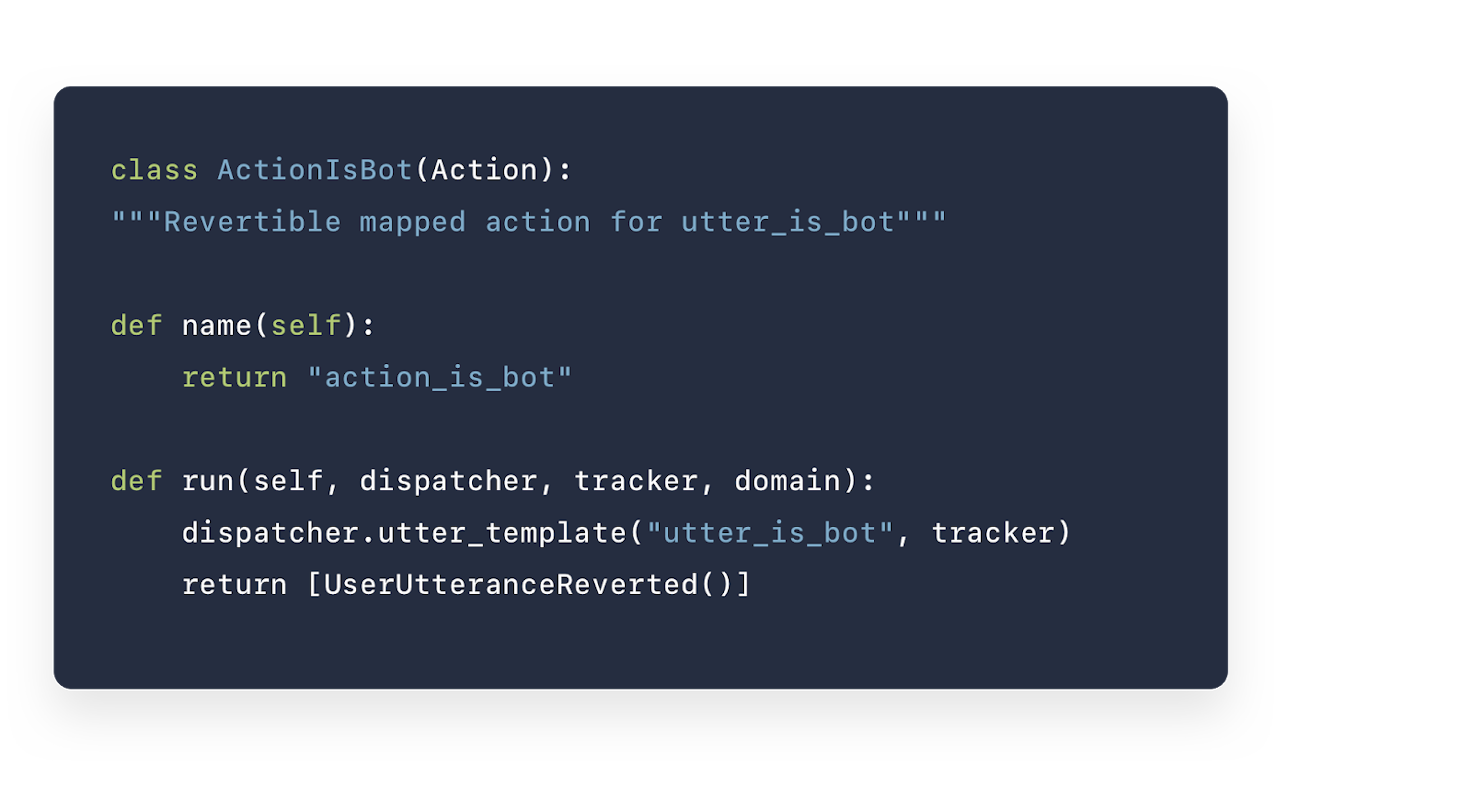
Preventing mapped actions from influencing later predictions
When a mapped action has been triggered, that action is taken into account by other policies making later predictions, just like any other conversational turn. If you want to completely remove the mapped action from the conversational flow, so it doesn't influence later predictions, you can disable the behavior by adding the UserUtteranceReverted() event to your custom action. This deletes the interaction from memory so it won't affect the predictions of other policies later in the conversation.
Keras Policy
The Keras Policy applies the power of machine learning to dialogue management. It learns from training data, and over time, your assistant can learn to handle advanced conversations. The policy uses the neural network implemented in Keras, a Python deep learning library. The default architecture is based on Long Short Term Memory (LSTM), a type of recurrent neural network (RNN) but this can be overridden in the Keras Policy model_architecture method.
The Keras policy considers multiple factors when making a prediction, including:
- The last action
- The intents and entities extracted by the NLU model
- The slots that have been set
- Previous conversational turns
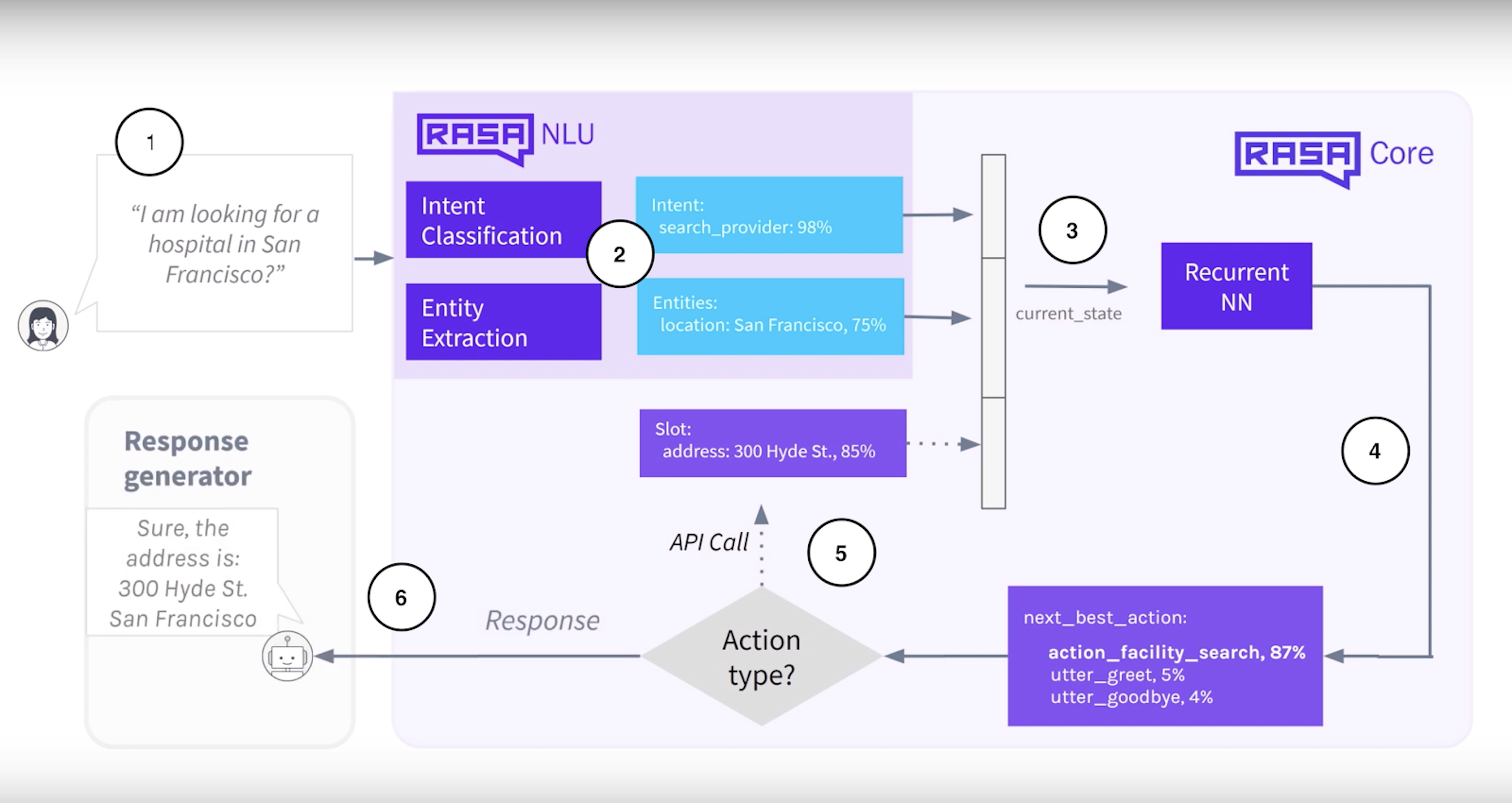
Let's walk through the process step by step to understand how the Keras Policy decides which action to predict.
- First, the user asks a question.
- Rasa NLU extracts the intents and entities from the user's message, which are used to create the feature vector passed to the dialogue model. A feature vector is a numeric representation that describes important characteristics of the message.
- The dialogue model takes in previous conversational states, as set by the max_history hyperparameter, and the feature vector of the current state is also passed into the model.
- The model predicts the next best action.
- If the next action includes a call to a backend integration that fetches additional details, those details can be featurized and used to predict future actions.
- The predicted response is sent back to the user.
Configuration
- Max_history - Defines the number of previous conversational states the model should take into account
- Epochs - The number of times the algorithm should pass through the training data, where an epoch equals one forward pass and one backward pass of all training examples.
- Validation_split - The portion of training data set apart and not used for training, to evaluate the model's performance
- Random_seed - Helps the model achieve reproducible results, when set to an integer value. By design, neural networks use randomness to achieve the best performance: in the initial weights set in a neural network, the training data that's sampled, and in other areas. The seed number is the starting point used by the random number generator to generate a random sequence; when we specify a random_seed value, the same starting point is used each time, resulting in the same random number sequence.
Embedding Policy (TEDP)
Transformer Embedding Dialogue Policy, also known as TED Policy, is Rasa's newest machine learning based policy. Compared to other machine learning policies like Keras, our research has shown that TED Policy performs better, especially when it comes to modelling multi-turn conversations.
Instead of using a recurrent neural network like Keras Policy, TED Policy uses Transformer, a deep machine learning model that is now overtaking RNNs in popularity. Transformers produce accurate results across a variety of corpora, or datasets, and they also deal well with unexpected user input, like adversarial messages or chitchat.
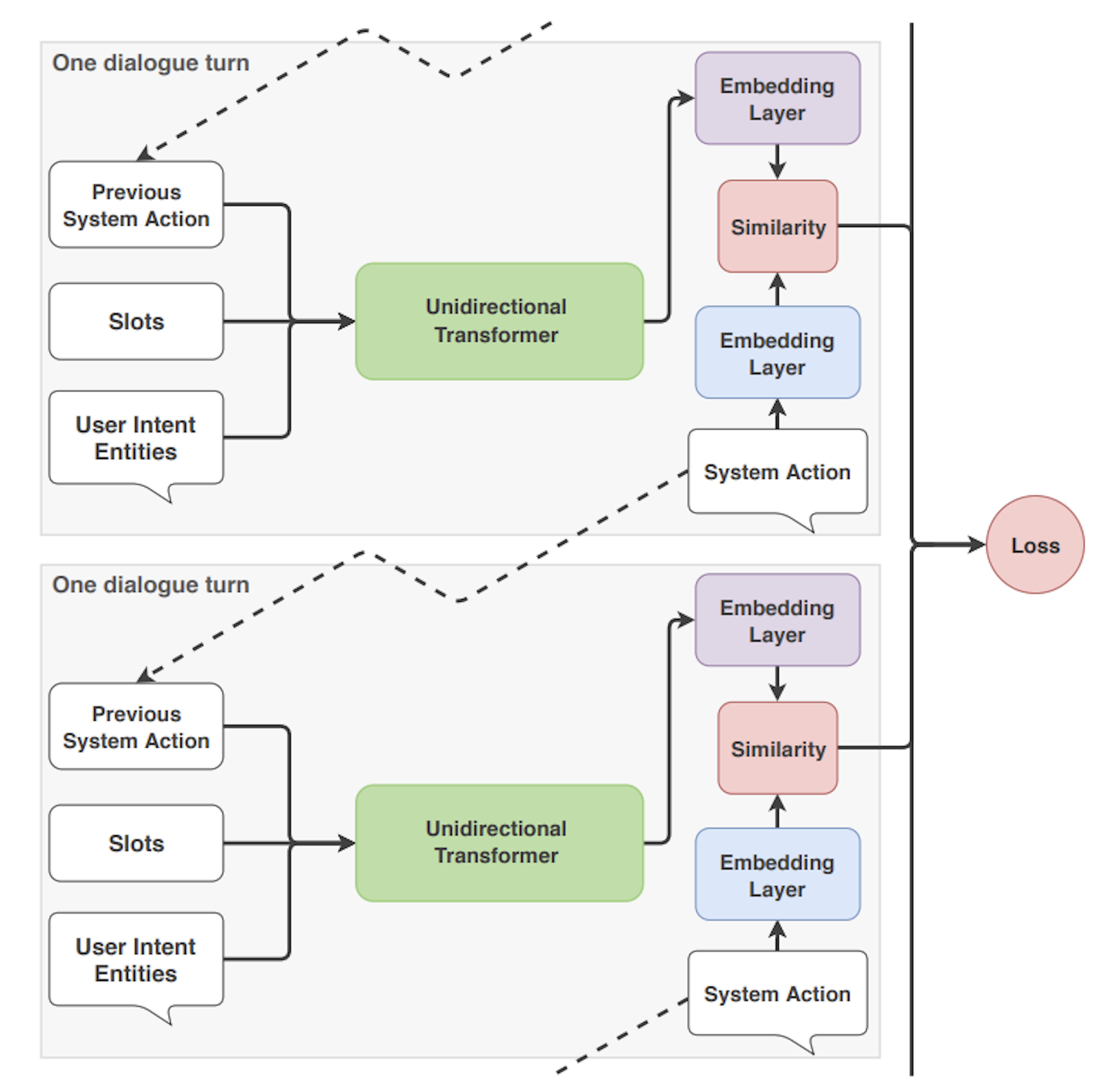
How does the TED Policy make predictions? Let's walk through the high level architecture (shown in the diagram below). The diagram depicts two time steps, or dialogue turns.
- First, input is aggregated from a variety of sources:
- Intent and entities extracted from the user's message by the NLU model
- Any previous system actions
- Data saved as slots.
These are concatenated into an input vector and fed into the transformer deep learning model.
- A dense layer is applied to the transformer's output to get dialogue embeddings for each time stamp.
- A dense layer is applied to create embeddings for each categorical system action, for each time step.
- The similarity between the dialogue embedding and the embedded system actions is calculated (this concept is based on the StarSpace idea).
Configuration
The TED Policy includes configurable hyperparameters that allow developers to adjust conditions that affect the neural network architecture, training, embedding, and more. See the documentation for a full list of hyperparameters and their default values.
Form Policy
The Form Policy is used in situations where the assistant needs to collect specific pieces of information from the user before executing an action. For example, in order for the Medicare Locator assistant to fetch search results for medical facilities, it needs two pieces of information: the type of facility and the location. Without those, it's impossible to complete the search request. If we were to develop the medicare locator assistant further, we might want to ask for additional information, like the patient's name and age, in order to send these details to the hospital ahead of the patient's visit.
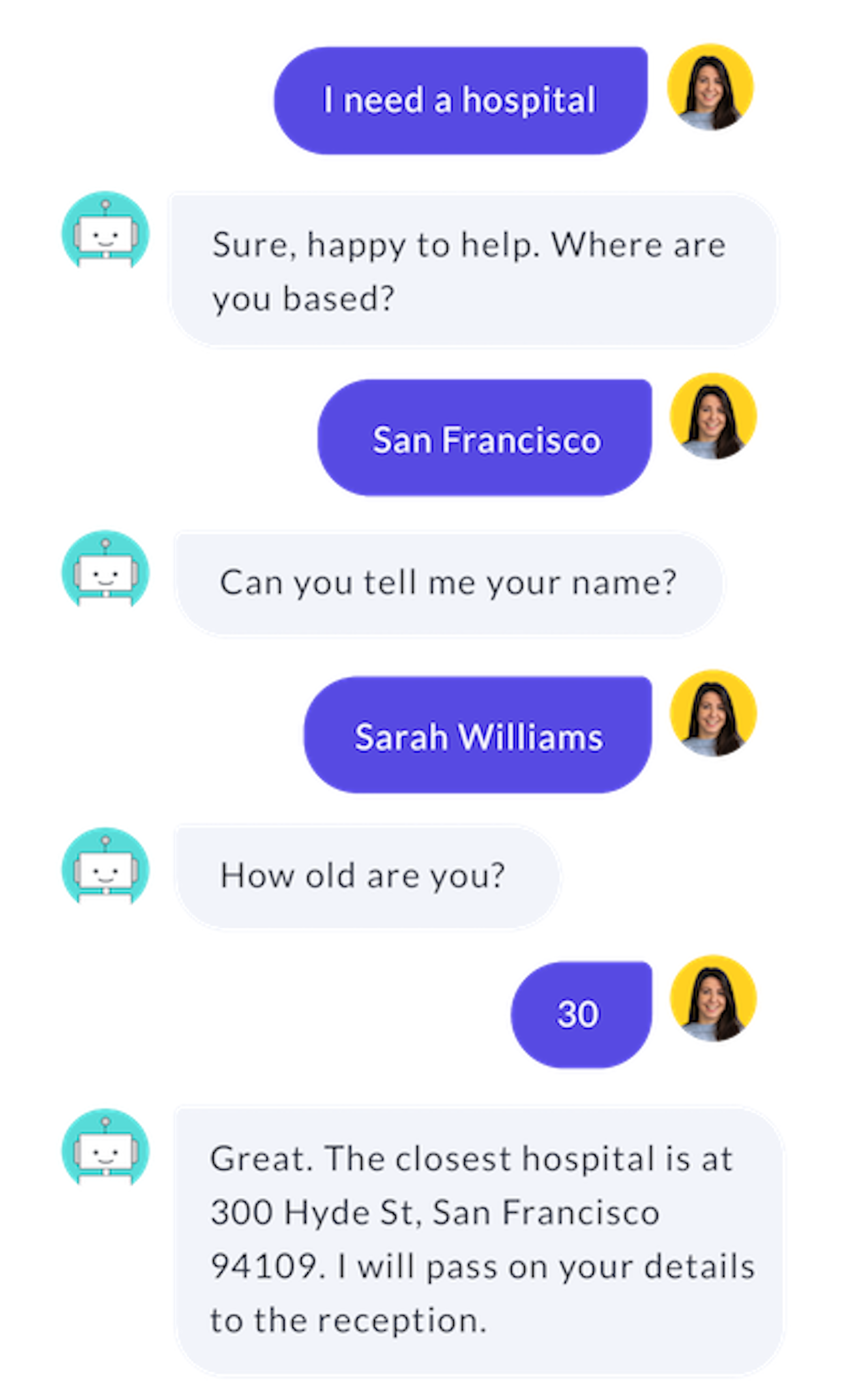
Another common use case is account creation. You might have a minimum number of fields that are required to create an account in a CRM or billing system-things like name, address, phone number, etc. If you were building an assistant that helps users create a new account, you would want to be sure that the assistant collected all of the required pieces of information from the user before moving forward in the conversation.
You could enable this behavior by writing stories with slots, but that would require a lot of training data, even just to handle the happy path. A better solution is to use the Rasa FormPolicy to collect the information. The FormPolicy allows you to define which pieces of information the assistant needs to collect. It activates a form action, which runs continually until all of the required data has been provided by the user.
Forms are a powerful feature in Rasa, and there's more to the topic than we can cover here. We'll dedicate the next episode to covering forms in greater detail.
Fallback Policy
Even the best contextual assistants get stumped from time to time, if the user's message is outside of the assistant's domain or off-topic. Since it's impossible to train your assistant to handle every possible situation, it's important to have a strategy for gracefully handling requests the assistant doesn't understand.
The Fallback Policy is activated when the assistant can't predict an intent or next action with certainty above a certain threshold. The Fallback Policy also kicks in when the confidence levels of two intents are very close together. The confidence levels that should trigger the fallback policy are configured as hyperparameters. When the Fallback Policy is triggered, an action is executed-usually an utterance letting the user know the assistant didn't understand and asking them to rephrase their message.
Configuration
The Fallback Policy accepts four hyperparameters that set the minimum confidence thresholds for triggering the fallback. These are:
- nlu_threshold - Min confidence needed to accept an NLU prediction
- ambiguity_threshold - Min amount by which the confidence of the top intent must exceed that of the second highest ranked intent.
- core_threshold - Min confidence needed to accept an action prediction from Rasa Core
- fallback_action_name - Name of the fallback action to be called if the confidence of intent or action is below the respective threshold. You can use the default fallback action, or you can configure your own. If you specify your own custom action, be sure to include it in your domain.yml and stories.md files.
Two-stage Fallback Policy
The Two-stage Fallback Policy is a more sophisticated variation of the Fallback Policy we just discussed. Instead of immediately executing the fallback action, the Two-stage Fallback Policy asks the user to verify the predicted intent. If the user verifies the intent was correct, the story continues. If the user tells the assistant the predicted intent was not what they meant, the assistant asks the user to rephrase the message.

Besides providing a better user experience, the Two-stage Fallback Policy also allows the assistant to correct itself and recover in cases when it's not confident in a prediction.
While dialogue policies are meant to be used together, a notable exception is the Fallback Policy and the Two-stage Fallback Policy. You can't choose both when configuring your dialogue policies in the config.yml file-it has to be one or the other.
Configuration
In addition to the nlu_threshold, ambiguity_threshold, and core_threshold hyperparameters, the Two-stage Fallback Policy also includes three more hyperparameters that define the actions executed at each stage of the fallback flow:
- fallback_core_action_name - Name of the fallback action called when the confidence of the Rasa Core action prediction is below the core_threshold. This action suggests possible intents for the user to choose from.
- fallback_nlu_action_name - Name of the fallback action to be called if the confidence of the Rasa NLU intent classification is below the nlu_threshold. This action is called when the user denies the second time
- deny_suggestion_intent_name - The name of the intent used to detect that the user has denied the suggested intents
Conclusion
Customizing your policy configuration and fine-tuning parameters is a powerful way to take your Rasa assistant to the next level. Although the default configuration provided with moodbot is a great place to get started, over time, you can layer on additional policies to enhance your assistant's performance.
In our next episode, we'll dive deeper into developing the medicare locator assistant, focusing on implementing custom actions with backend integrations, forms and fallback. Keep up the momentum, and if you get stuck, ask us a question in the Community forum.
Additional Resources
- Ep #7 Rasa Masterclass - Dialogue Policies (YouTube)
- Dialogue Policies (Rasa docs)
- Dialogue Transformers (arXiv)
- StarSpace: Embed All the Things! (arXiv)
- Fallback Actions (Rasa docs)
- Failing Gracefully with Rasa (Rasa blog)