



Many AI assistants don't use as much machine learning as you might think. While it's common practice to apply machine learning to NLU, when it comes to dialogue management, many developers still fall back to rules and state machines.
At Rasa, we've challenged the assumption that you should build an AI assistant by just adding more and more rules over time. Instead, using machine learning to select the assistant's response presents a flexible and scalable alternative. The reason for this is one of the core concepts of machine learning: generalization.
When a program can generalize, you don't need to hard-code a response for every possible input because the model learns to recognize patterns based on examples it's already seen. This scales in a way hard-coded rules never could, and it works as well for dialogue management as it does for NLU.
Rasa Open Source uses machine learning to select the assistant's next action based on example conversations, supplied as training data. Instead of programming an if/else statement for every possible conversation turn, you provide example conversations for the model to generalize from. And when you need to support a new conversation path? Instead of trying to reason through updating an existing, complex, set of rules, you add example conversations to your training data that fit the new pattern. This approach doesn't just apply to simple back and forth conversations-it makes it possible to support natural sounding, multi-turn interactions.
In this blog post, we'll explore dialogue management by unpacking one of the machine learning policies used in Rasa Open Source. The Transformer Embedding Dialogue Policy, TED for short, is just one of the dialogue policies used by Rasa Open Source to select which action the assistant should take next. It uses a transformer architecture to decide which dialogue turns to pay attention to and which to selectively ignore when making predictions.
Modeling Multi-turn conversations
A Rasa assistant uses multiple policies in its configuration to decide which action to take next. Some dialogue policies are optimized for simple tasks like matching the current conversation with one in the training data while others, like the TED policy, are suited for modeling conversations where previous context is needed to choose the most appropriate next action. When it's time for the assistant to respond to the user, all of the policies in the assistant's configuration make a prediction about what the next best action should be, and the policy with the highest confidence in its prediction determines the action that's taken.
The TED Policy performs particularly well on non-linear conversations, where the user interjects with an off-topic message or loops back to modify an earlier statement. These types of multi-turn dialogues reflect the way users actually talk, and they're also the types of dialogues that are particularly complex to try to model with a set of rules.
What do we mean by non-linear conversations? Imagine a conversation where you could only remember the most recent thing the other person had said to you. You'd probably miss a lot of cues and make a lot of mistakes! Real conversations tend to move back and forth between topics or digress and then return to the main topic. One way to visualize this pattern is to think of a conversation as a set of layered segments, where portions of a conversation directly respond to one another. Each segment doesn't necessarily relate to the topic covered immediately before, and multiple segments can be in play simultaneously.
One example is a sub-dialogue: a pattern where the conversation takes a brief detour. In the conversation below, the user circles back to verify the credit on the account before proceeding with the main goal, making a purchase. The user then returns to the credit topic after the purchase is complete.
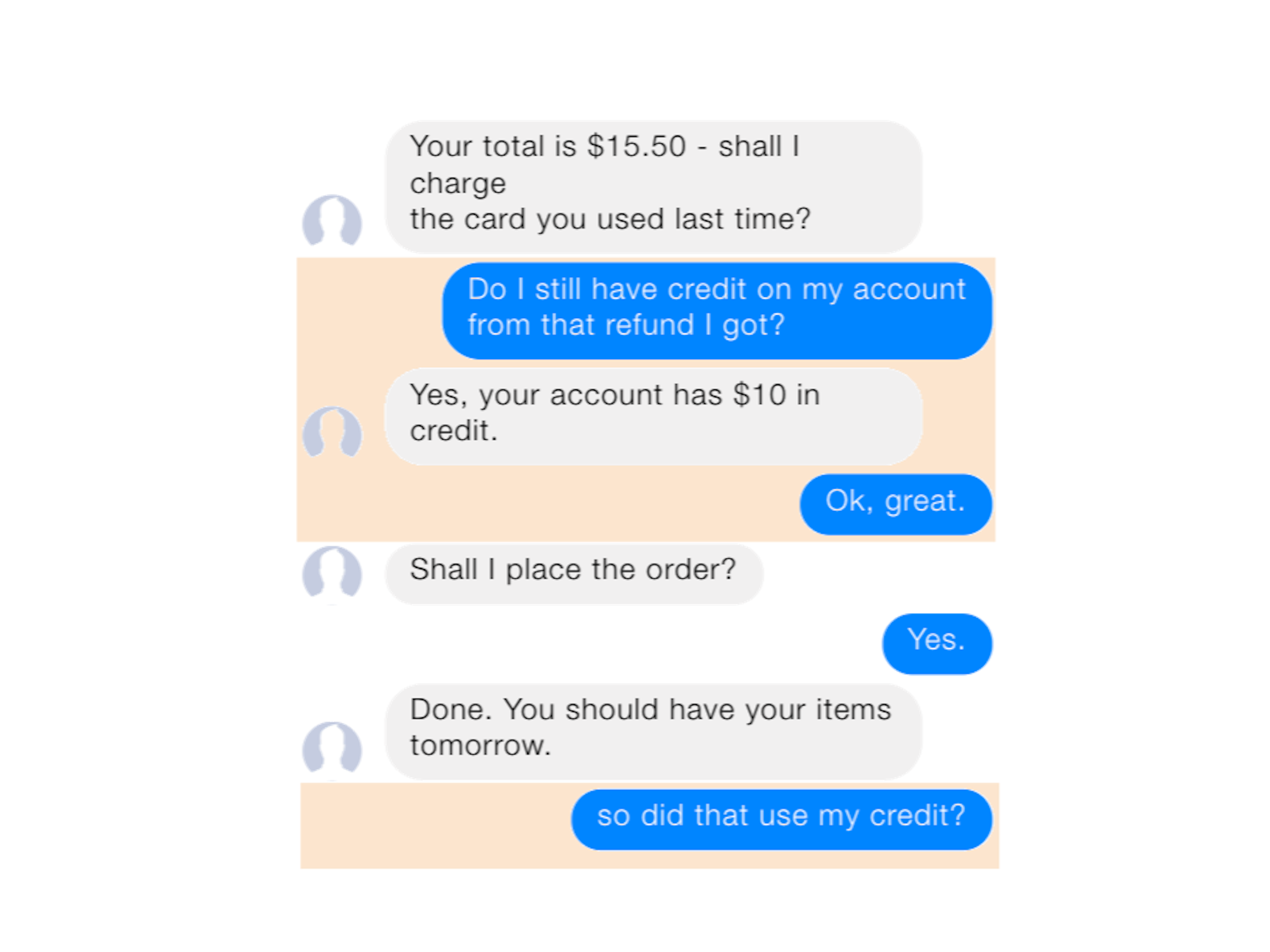
Another common, non-linear example is chitchat, statements or questions that aren't related to the user goal or task at hand. If the user were to ask "Are you a bot?" mid-conversation, the assistant should reply to the question and then return to the previous task. Similarly, if the user wants to modify an earlier request, the assistant should be able to keep up and read the context to make the necessary adjustments.
As users change topics, the complexity an assistant needs to deal with in order to keep up with what's relevant increases. Let's look at another conversation, with related topics organized by color:

Situations like this can be challenging, because while the entire conversation history might not be needed to determine the next action, there's no limit to how far back in the conversation history a user might reference. Consider the nested logic that would be required to handle this conversation elegantly, using hard-coded rules. A better alternative is a machine learning-based approach, which can untangle the layered topics to sort out what's important and what's irrelevant.
Transformers vs Recurrent Neural Networks
The most common approach to handling these types of dialogues has been to use an architecture called a recurrent neural network, or RNN. By default, an RNN commits every user input to memory. While in theory an RNN should be able to produce accurate predictions across a broad range of conversation types, the reality is that without a very large body of training data, RNNs often fail to correctly generalize.
When it comes to modeling dialogue turns, there are some clear drawbacks to encoding every user input. It's resource-intensive, and not every dialogue turn is relevant to the current conversation state. Long Short-Term Memory (LSTM) networks are a type of RNN that aim to address this by learning to forget parts of the conversation.
Increasingly though, LSTMs are being replaced by transformer architectures, which are especially well-suited for modeling multi-turn dialogues. Unlike LSTMs, transformers don't encode the entire sequence of user inputs. Instead, a transformer uses a mechanism called self-attention to choose which elements in the dialogue to take into account when making a prediction, independently at each turn. This is in contrast to an LSTM, which updates its internal memory and then passes the state to subsequent dialogue turns.
If an LSTM encounters an unexpected user input, it can wind up in a state it can't recover from, because memory is passed from one conversation turn to the next. A transformer is better able to recover from unexpected inputs because the relevance of the conversation history is re-calculated within each turn.
To summarize, a transformer architecture offers two advantages when it comes to predicting dialogue across more complex, multi-turn conversations. It can decide which elements in the dialogue sequence are important to pay attention to, and it makes each prediction independently from the others in the sequence, so it's able to recover if a user interjects with something unexpected.
How the TED Policy works
Let's take a high-level look at what's happening when the TED policy makes a prediction, from input to output. If you want to go deeper, you can find an explanation of the process in our paper.
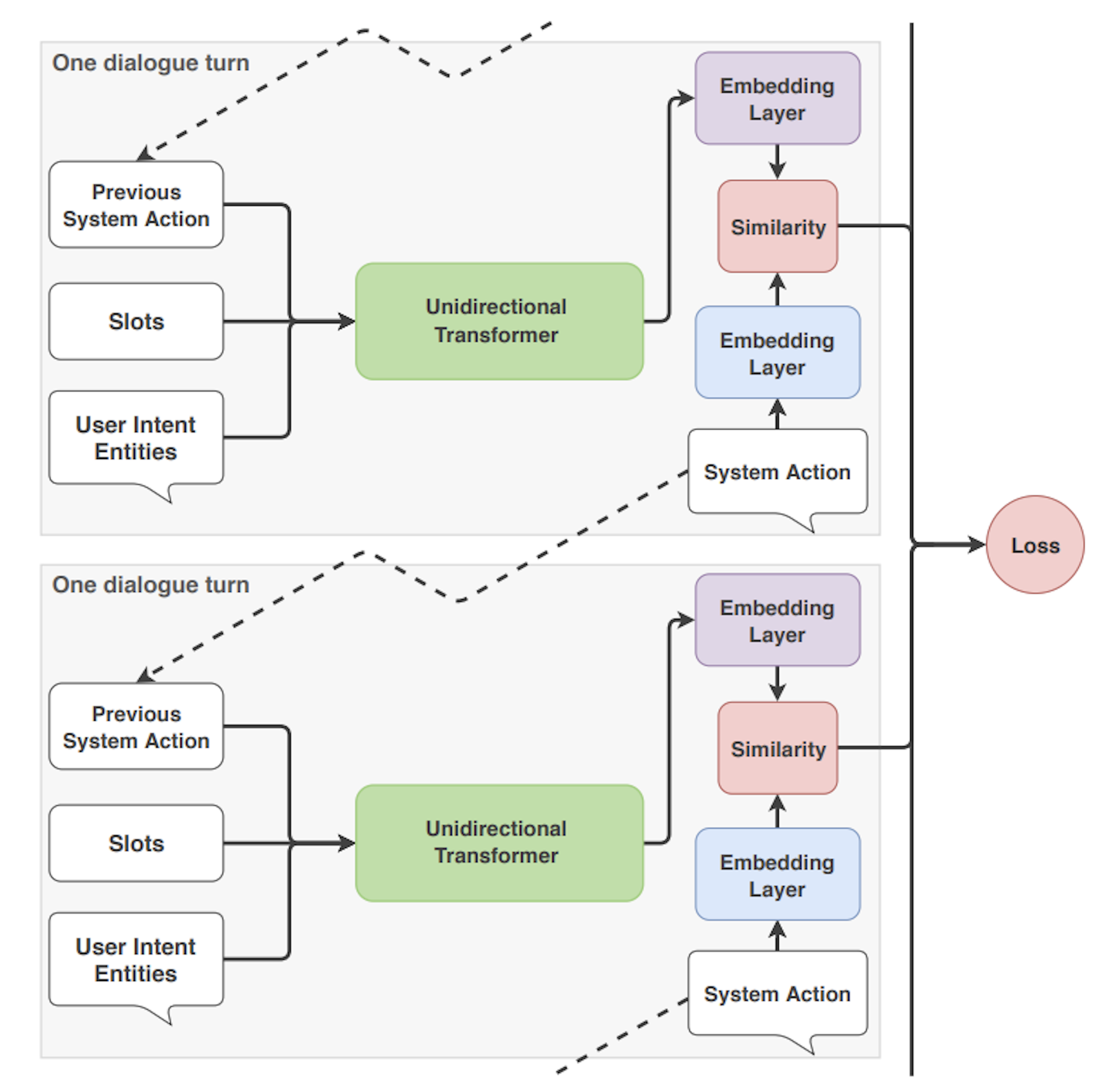
At each dialogue turn, the TED policy takes three pieces of information as input: the user's message, the previous system action that was predicted, and any values saved to the assistant's memory as slots. Each of these is featurized and concatenated before being fed into the transformer.
Here's where the self-attention mechanism comes into play: The transformer accesses different parts of the dialogue history dynamically at each turn and then assesses and recalculates the relevance of previous turns. This allows the TED policy to take a user utterance into account at one turn but ignore it completely at another, which makes the transformer a useful architecture for processing dialogue histories.
Next, a dense layer is applied to the transformer's output to get embeddings-numeric features used to approximate the meaning of text-for the dialogue contexts and system actions. The difference between the embeddings is calculated, and the TED policy maximizes the similarity with the target label and minimizes similarities with incorrect ones, a technique based on the Starspace algorithm. This process of comparing the similarities between embeddings is similar to the way intent classifications are predicted by the EmbeddingIntentClassifier in the Rasa NLU pipeline.
When it's time to predict the next system action, all possible system actions are ranked according to their similarity, and the action with the highest similarity is selected.
This process is repeated across each dialogue turn, as seen below.
The TED Policy in Practice
How much of the inner workings of the TED policy do you need to understand to use it as a developer? The answer is that you can go as deep or as shallow as you want. The policy is configured with defaults that perform well across most use cases, but if you want to fine tune your model, you can configure hyperparameters to get the best performance on your specific data set.
Configure the TED policy by listing the EmbeddingPolicy in the assistant's config.yml file, along with optional hyperparameters:
policies:
- name: "EmbeddingPolicy"
While the TED policy is great for handling multi-turn conversations, it isn't the only policy you'll need in your configuration. Additional Rasa dialogue policies are optimized for different dialogue patterns, and not all of them use machine learning. For example, the Form policy enforces business logic, like the need to collect certain pieces of required information before executing an API request. In practice, you could say this looks a lot like rules. Other policies do things like mimic dialogues that already exist in the training data, execute a fallback behavior if the model's confidence is low, or map a specific response to an intent, for cases where an intent should always have the same answer. You can learn more about dialogue policies in Rasa and how they complement each other by watching episode 7 of the Rasa Masterclass.
Conclusion
As long as users talk like, well, humans, developers building AI assistants will need to anticipate user input that doesn't follow a straight line. Interjections, off-topic requests, clarifications and corrections all come with the territory.
A system of rules and if/else statements might be a logical way to handle response actions at first, but over time, adding to these systems becomes increasingly difficult. We believe machine learning policies that can generalize by picking up patterns from example conversations are the new standard for building AI assistants, and with the TED policy, AI assistants can respond appropriately to the kinds of complex conversations needed to get to Level 3.
The Rasa research team is working to put applied research like the TED policy into the hands of developers running mission-critical AI assistants. Keep up with new developments by following Rasa on Twitter and in the forum.